Исследование результатов узла Дерево решений
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Окно просмотра узла Дерево решений состоит из нескольких вкладок. Ниже представлено краткое описание каждой вкладки:
-
Основные параметры дерева – отображает базовую информацию: размер и форму сгенерированной модели:

На вкладке Основные параметры дерева количество нетерминальных узлов есть число узлов, у которых имелось разветвление на нижнем уровне дерева. Терминальные узлы – это узлы, которые являются "листьями" данного дерева. Чем больше нетерминальных узлов, тем больше, или шире, дерево. При сравнении этого параметра с другими значениями мы можем определить, шире это дерево или глубже, имеет ли оно больше ветвей или больше уровней. Количество листьев – это число терминальных узлов, где находятся прогнозы целевой переменной. Прогноз представляет собой приблизительную оценку значений. Глубина построенного дерева – это количество листьев. Каждое дополнительное разбиение переменной добавляет еще один уровень. Глубина – это число таких уровней. Этот параметр может использоваться в сравнении с шириной дерева для определения того, какой параметр дерева больше – глубина или ширина.
-
Эффективность классификации – отображает данные об эффективности классификации:
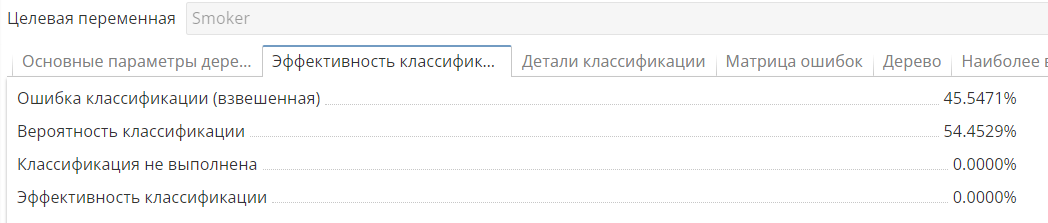
-
Детали классификации – отображает результаты классификации в табличном формате с указанием таких метрик, как Полнота и Точность, а также с указанием типов ошибок классификации:

-
Матрица ошибок наглядно отображает разницу между фактическими и спрогнозированными значениями:
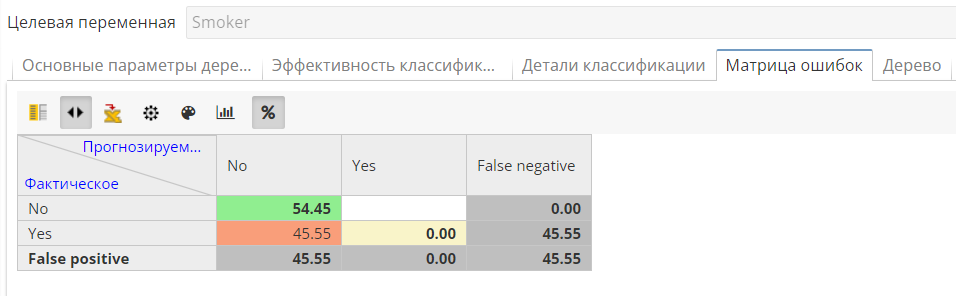
-
Дерево – отображает интерактивное дерево сгенерированной модели;
-
Наиболее важные правила – отображает наиболее важные правила, полученные из терминальных узлов дерева. Каждое правило отделяет часть таблицы, выделяет в ней класс или кластер на основе значений прогнозирующих переменных;
-
Значимость независимых переменных – содержит график, указывающий на относительную значимость различных предикторов, использованных в модели для получения оценки целевой переменной. Доля таблицы, % – показатель того, какая часть таблицы была разделена на классы с помощью конкретного предиктора:
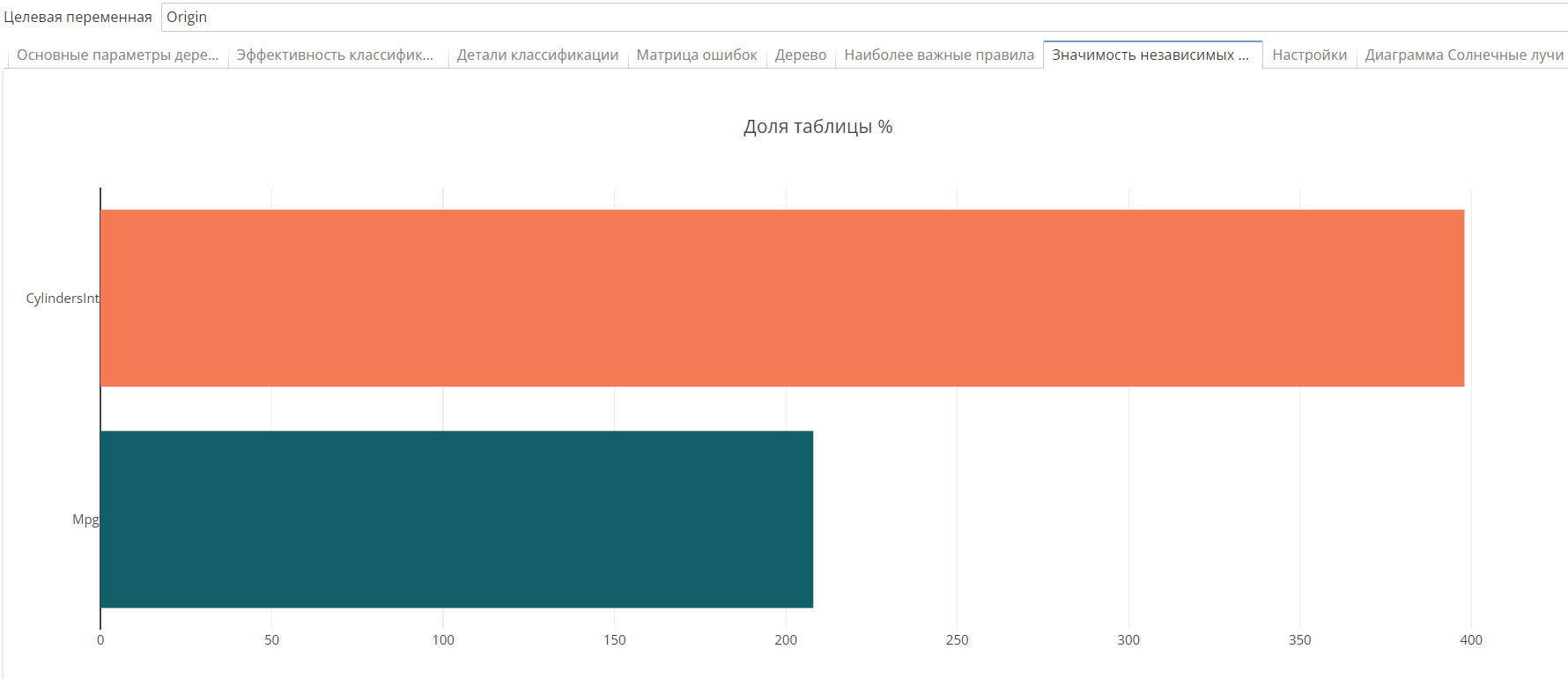
-
Настройки – отображает информацию о выполнении узла, например, сколько времени понадобилось узлу для завершения работы и какие настройки были применены.
-
Диаграмма Солнечные лучи - отображает результаты в виде диаграммы солнечных лучей.
Работа с вкладкой Дерево
Вкладка Дерево содержит созданную узлом модель решений.
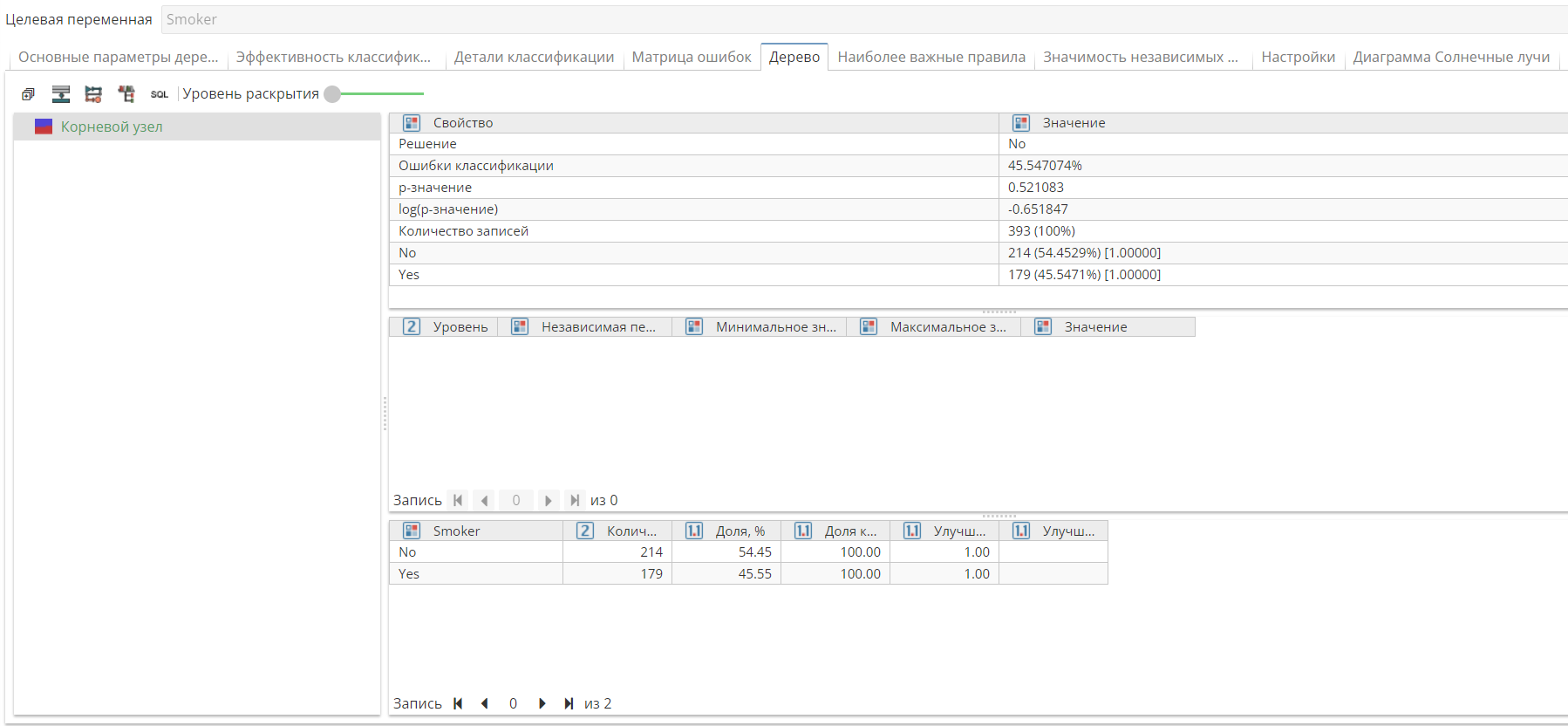
Вы можете исследовать эту модель, исследуя настройки различных "узлов" или отдельных элементов внутри дерева (узлов дерева). Термин "узлы дерева" не следует путать с узлами PolyAnalyst, которые можно добавить на скрипт. Используйте слайдер над деревом, чтобы отобразить или скрыть уровни дерева, либо используйте символы + и -. На правой панели отображаются статистические параметры для текущего выбранного узла (здесь мы опять имеем в виду не узел скрипта, а узел дерева). Эти статистические параметры означают, какие записи оказались в выбранном узле. Мы используем термин "корень", чтобы обозначить самый верхний узел дерева. Ветви означают участки дерева, ведущие к листьям. Ветви также называются разветвлениями. Отдельная ветка означает "решение" или точку, в которой алгоритм выполняет разделение более крупного набора записей на два или более наборов записей. Узел без дочерних узлов называется листовым узлом. Листовые узлы – самые нижние узлы дерева.
Таблица в нижней правой части окна отображает некоторые количественные характеристики выбранного в дереве узла в ряде колонок:
-
Количество записей отображает количество исходных записей каждой категории, которые вошли в данный узел дерева.
-
Доля отображает долю записей с целевым значением в текущем узле по отношению к общему количеству записей в данном узле.
-
Доля категории, % отображает долю записей с целевым значением в текущем узле по отношению к общему количеству записей в исходной таблице.
-
Улучшение отображает, на сколько процент записей с целевым значением в данном узле больше по сравнению со средним процентом таких записей. На первом уровне дерева, следующим за Корневым узлом, значения в колонках Улучшение и Улучшение родителя совпадают, поскольку у узлов первого уровня нет родителя. Начиная со второго уровня, в последней колонке Улучшение родителя будет отображаться, на сколько процент записей данной категории в выбранном узле больше по сравнению родительским узлом.
Каждый отдельный узел, кроме корневого, представляет собой условие, подобное тому, что используется в узле Фильтрация строк. Оно позволяет выделить конкретный подмассив записей, который соответствует этому условию. Например, условием может быть "все записи, где значение в колонке А больше 5". Перемещаясь вниз по дереву от корня к листьям вы имеете дело все с меньшим количеством записей.
Каждое условие применяется через пересечение. Допустим, имеется дерево с корневым узлом A, узлом B – дочерним узлом A, и узлом C – дочерним узлом B; все вместе они представляют собой трехуровневое дерево; тогда, при просмотре записей, распределенных в узел C, узел C представляет пересечение всех записей в узлах A, B и C. A, корневой узел, не имеет условий, т.к. корневой узел содержит все исходные записи. Другими словами, узел C содержит только те записи, которые отвечают условию узла B и условию узла C. В том же примере дерева, если вам нужно исследовать B, вы получите все записи, которые соответствуют условию B независимо от C. Таким же образом, если бы имелся узел D, который был бы дочерним узлом C, то в него вошли бы только те записи, которые соответствовали бы всем условиям узлов A, B, C и D. Обратите внимание на булев оператор "AND", который означает пересечение.
"Условие", которое определяет каждое разветвление (каждый дочерний узел с разветвлением) – это основной булев оператор истина/ложь. Он абстрактный, поскольку условия могут варьироваться. Например, если условие применяется к числовой колонке, то условие может содержать значения >, >=, <, ⇐, или =. Если условие применяется к колонке "истина/ложь", то условие может содержать значения, которые в данной колонке являются истинными или неистинными (ложными). Таким же образом, для категориальной строковой колонки условие может быть таким, в котором значения колонки соответствуют указанному значению.
Этот сложный математический процесс можно упрощенно описать следующим образом: разветвление происходит для того, чтобы сделать подмассивы данных однородными относительно уникальных значений (классов) целевой переменной. Например, если целевая переменная – категориальная колонка со значениями A, B и C, при каждом разветвлении алгоритм пытается разделить исходный массив данных разделить на подмассивы, в которых записи, назначенные для каждого подмассива, содержат только одно из данных значений. PolyAnalyst может сгенерировать дерево с тремя дочерними узлами, при этом первый дочерний узел будет содержать только те записи, в которых прогнозируемое значение целевой переменной – A, второй дочерний узел будет содержать только те записи, в которых прогнозируемое значение – B; то же относится и к третьему дочернему узлу.
Если вы хотите выполнить дальнейший анализ с отдельным подмассивом данных, вы можете выбрать узел, представляющий эти записи, а затем использовать одну из опций панели инструментов, расположенной над деревом, чтобы сгенерировать подмассив записей. Новые узлы будет автоматически соединены с узлом, который используется как входной для узла Дерево решений. Например, выберите узел дерева и нажмите кнопку Создать узел Фильтрация строк на панели инструментов. PolyAnalyst сгенерирует новый узел Фильтрация строк. Кнопка Создать узел "Производные колонки" автоматически генерирует новый узел Производные колонки, который включает одну новую колонку. Новая колонка является булевской, и содержит значения "истина" или "ложь". Колонка содержит значение "истина", если запись отвечает условиям, в противном случае колонка имеет значение "ложь". Вы также можете создать новый узел Таксономия. Для этого нажмите кнопку Создать узел "Таксономия" и задайте параметры Наименьшая поддержка и Уровень расшифровки. Новые узлы автоматически создадут SRL-выражение, которое соответствует условию, используемому для выделения подмассива в дереве.
Если вам не нужен этот подмассив данных, но вы хотите скопировать SRL-выражение, используемое для создания этого подмассива, используйте кнопку Скопировать выражение на панели инструментов.