Подготовка данных
Общие сведения о подготовке данных к анализу
"Дайте мне шесть часов на то, чтобы срубить дерево, и первые четыре часа я буду точить топор".
- Авраам Линкольн
Теперь необходимо подготовить данные к анализу. Часто на подготовку данных может понадобиться больше времени, чем на сам анализ, это один из наиболее важных этапов обработки данных, который позволяет отличить опытных аналитиков от начинающих. Здесь всегда действует правило: что посеешь, то и пожнешь. Наилучший результат не всегда можно получить с помощью каких-то сложных моделирующих инструментов. Гораздо полезнее иногда оказывается тщательная очистка и организация данных непосредственно перед началом анализа. Вероятность получить качественный и полезный результат выше, если вы будете анализировать качественные данные.
К операциям подготовки данных относятся выявление выбросов, восстановление пропущенных значений, нормализация данных, удаление повторов и исправление орфографических ошибок.
Итеративность
Очистка данных - это настолько важный этап анализа данных, что она часто выполняется итеративно, в несколько операций. Это происходит по двум причинам. Во-первых, на начальном этапе работы пользователь часто не представляет в полной мере, насколько несовершенны исходные данные, и лишь позже в процессе работы он может обнаружить какие-то ошибки. Во-вторых, существует зависимость между качеством аналитической модели и чистотой данных. Некоторые типы моделей очень чувствительны к отдельным видам ошибок, другие же в меньшей степени зависят от ошибок.
Например, при работе с текстовыми данными мы почти всегда исправляем в них орфографические ошибки. Если же говорить о грамматических ошибках, возможны разные сценарии: все зависит от типа модели, которую вы намерены создать позже в вашем проекте. PolyAnalyst способен выполнять очень сложные поисковые запросы, используя парсеры на основе грамматики зависимостей и составляющих. Эти парсеры позволяют эффективно разбивать предложение, что дает пользователю возможность конкретизировать грамматические и синтаксические отношения в запросе. В качестве примера рассмотрим следующие два предложения.
-
The engine fired up.
-
The engine caught on fire.
В обоих предложениях есть слова fire и engine, которые близко расположены друг к другу, но имеют разные значения. В первом случае слово fire используется как глагол, субъектом обозначаемого им действия является engine. Во втором же предложении это слово - часть фразового глагола, engine - объект обозначаемого им действия. Парсер на основе грамматики зависимостей полагает, что исходный текст не содержит грамматических ошибок. Если эти ожидания не оправдываются, например, в том случае, если текст представляет собой отдельные краткие (стенографические) заметки, парсинг на основе грамматики зависимостей может дать менее точный результат по сравнению с наивным подходом на основе близости слов. Если вы не собираетесь использовать парсер на основе грамматики зависимостей, исправлять грамматические ошибки вовсе необязательно.
Практические рекомендации
Операции по очистке данных можно условно разделить на три нечетких категории.
-
Операции, которые мы выполняем практически всегда, поскольку они просты и в большинстве случаев позволяют повысить точность результатов. Исправление орфографических ошибок - это пример операции, которую мы почти всегда выполняем при работе с текстовыми данными.
-
Операции, которые мы выполняем иногда, поскольку считаем, что это позволит повысить качество нашей модели. Так, например, мы иногда исправляем грамматические ошибки или выполняем факторный анализ, исходя из качества данных или модели, которую планируем создать.
-
Операции, которые мы не выполняем из-за ресурсных ограничений или отсутствия возможности их выполнить. Например, мы не считаем, что жалобы NHTSA являются заведомо ложными и не просим специалистов их верифицировать (за исключением случаев, когда мы создаем модели по выявлению мошенничества).
| Прежде чем приступать к очистке данных, помните, что, внося любые изменения в данные, вы рискуете тем, что набор данных может стать нерепрезентативным или неточным, а это может привести к безосновательным выводам. Чаще всего это происходит, когда пользователь принимает решение о том, какие записи сохранить в таблице данных, а какие удалить из нее. Всякий раз перед очисткой данных рекомендуем вам задавать себе следующие вопросы: 1) Какова природа ошибки? Легко ли она объяснима и велика ли ее вероятность? 2) Связана ли ошибка со свойством, которое вы намерены измерить? Например, случайно ли распределены отсутствующие значения или зависит ли наличие отсутствующего значения от другого значения, которое вы намерены измерить? |
Хороший пример: Исправление орфографических ошибок в жалобах NHTSA
В нашем проекте мы исправим орфографические ошибки в таблице с жалобами на транспортные средства, поступившими в NHTSA.
Какова природа ошибки? Легко ли она объяснима и велика ли ее вероятность? - Да, поскольку данные вводились вручную, ошибки могут быть допущены по невниманию или по незнанию.
Связана ли ошибка со свойством, которое вы намерены измерить? - Маловероятно, нас не интересуют орфографические навыки людей, подавших жалобы. У нас нет оснований полагать, что орфографические навыки как-то могут изменить саму суть заявленной в жалобе проблемы. Чаще всего орфографические ошибки допускаются случайно (кроме преднамеренного мошенничества).
Вывод: Исправление орфографических ошибок оправдано и не приведет к искажению данных.
Плохой пример: Ненадлежащий контроль за отсевом участников третьей фазы клинических испытаний медицинского препарата
Предположим, что вы оцениваете результаты третьей фазы клинических испытаний, позволяющих определить эффективность нового препарата против сквамозной карциномы. Произошел отсев 21 участника испытаний из 100 к середине курса. Что делать? Следует ли удалить их данные из таблицы? Попытайтесь ответить на те же вопросы:
Какова природа ошибки? Легко ли она объяснима и велика ли ее вероятность? - Ошибка возможна, хотя объяснить, почему произошел отсев, не так просто. Причины могут быть разные: кто-то мог почувствовать себя хуже и сделать вывод, что лекарство неэффективно, у кого-то могли проявится побочные эффекты, кто-то мог подумать, что участие в испытаниях - пустая трата времени, а кто-то и вовсе мог умереть из-за сквамозной карциномы или другого заболевания. Кто-то возможно, продолжает принимать препарат, но не может приходить на проверку регулярно, и так далее.
Связана ли ошибка со свойством, которое вы намерены измерить? - Да, можно считать, что одним из показателей эффективности лечения является отсев участников испытаний (участники с отрицательными результатами лечения скорее выйдут из эксперимента, чем те, кому лечение идет на пользу).
Вывод: Удаление данных отсеявшихся участников испытаний из таблицы может исказить результаты вашего анализа. Такой эффект известен под названием "Систематическая ошибка выжившего".
Индексирование данных
На ранних этапах проектов по анализу текстовых данных всегда выполняется индексирование текста. Индексирование позволяет разделить текст на отдельные слова или лексемы, расставить в нем метки, а также рассчитать статистику использования этих слов и лексем в таблице данных. Необходимость выполнения такой операции не совсем понятна (или неочевидна) в начале проекта, однако помните, что большинство текстовых узлов в PolyAnalyst работают именно с результатами индексирования текста. Если в проекте таким узлам не предшествует узел Индекс, текстовые узлы самостоятельно индексируют текст, что может замедлить выполнение проекта.
В разделе Текстовый анализ выберите узел Индекс, перетащите его на скрипт и соедините его с узлом Файлы CSV, импортировавшим таблицу данных NHTSA.
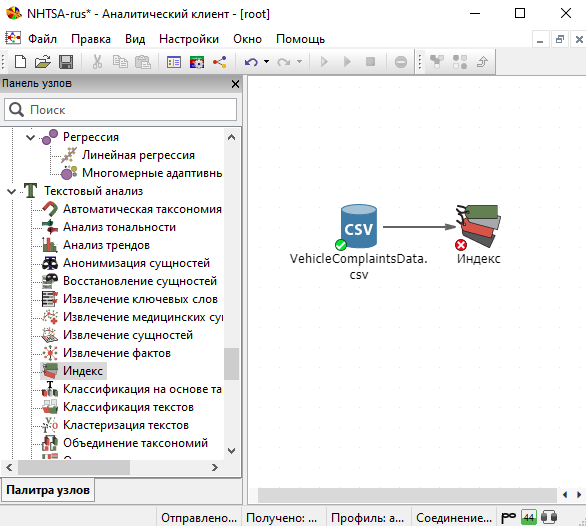
В окне Настройки выберите текстовую колонку Summary и нажмите Выполнить.
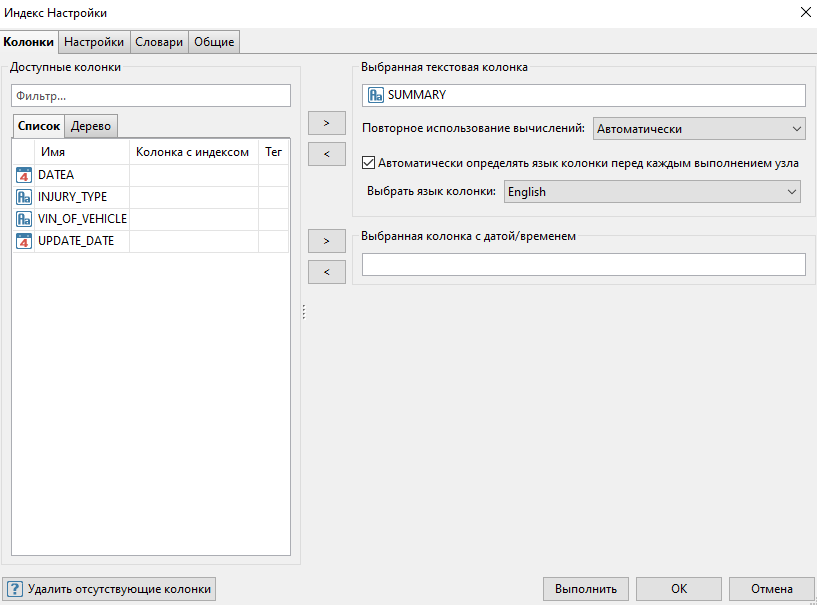
Дважды кликните по узлу Индекс, чтобы открыть окно просмотра результатов узла. Автоматически откроется вкладка Лексемы, на которой будут представлены основные результаты индексации исходного текста - лексемы, их части речи, поддержка и частота использования в таблице.
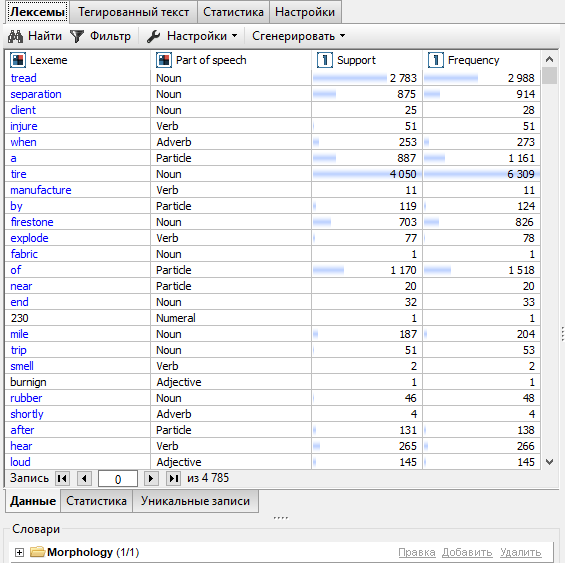
Лексема - единица языка, имеющая самостоятельное лексическое значение, почти всегда слово или фраза.
Поддержка: количество записей, в которых лексема встречается хотя бы один раз. Например, поддержка лексемы "injure" на скриншоте выше составляет 51, это значит, что это слово встречается в 51 записи в таблице.
Частота: общее количество случаев использования лексемы в таблице данных. Если лексема несколько раз встречается в записи, она засчитывается несколько раз. По этой причине частота лексемы всегда должна быть больше или равна ее поддержке.
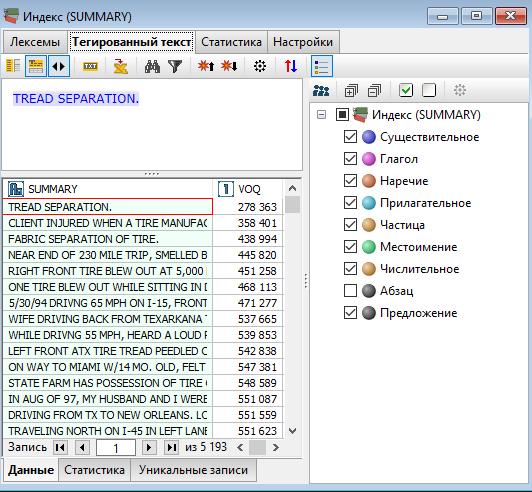
Узел Индекс также выполняет парсинг предложений и разметку лексем по частям речи (см. вкладку Тегированный текст).
Замена категорий
Выберите узел Замена категорий из раздела Операции с колонками в Палитре узлов и соедините его с узлом Индекс.
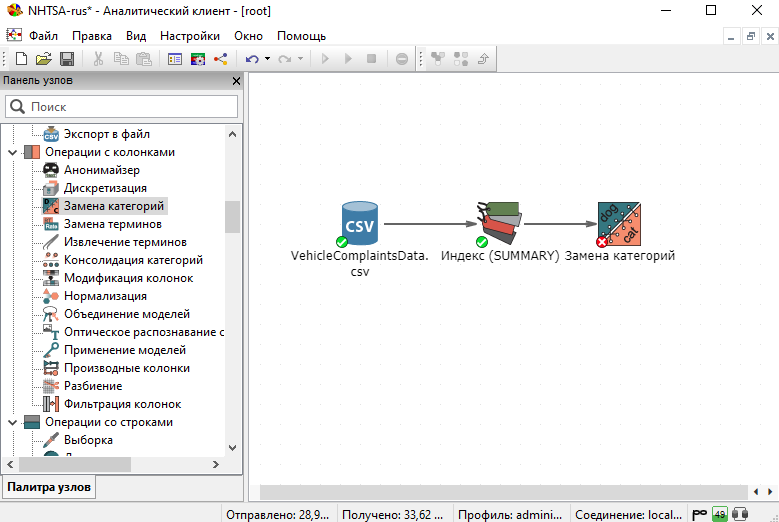
Узел Замена категорий позволяет пользователям заменять разные категориальные значения одним общим значением.
Выберите колонку VEH_MFR на вкладке Колонки в окне настроек узла и отметьте опцию Исключить источник.
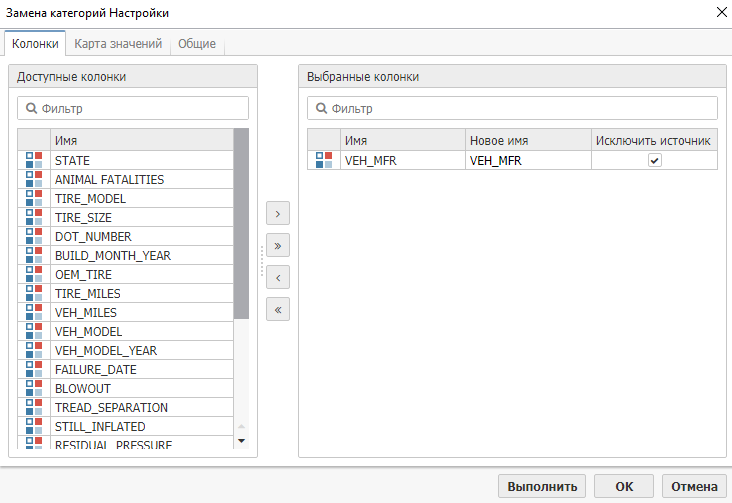
Перейдите на вкладку Карта значений и вручную замените все варианты написания названия модели Chevrolet/Chevy/Chevrolet Truck на единый вариант CHEVROLET. Для этого введите единое название в соответствующих ячейках колонки Выходы:
Выполните узел и просмотрите его результаты.
Создание производных колонок
Выберите узел Производные колонки из Палитры узлов и добавьте его на скрипт.
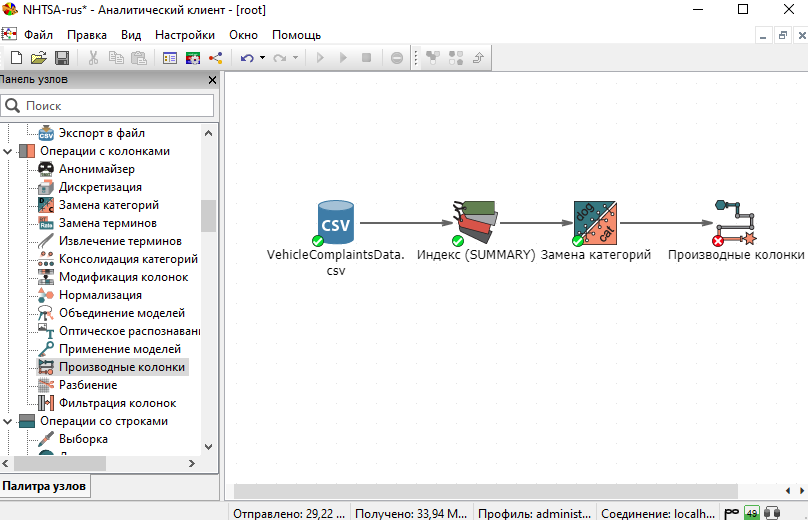
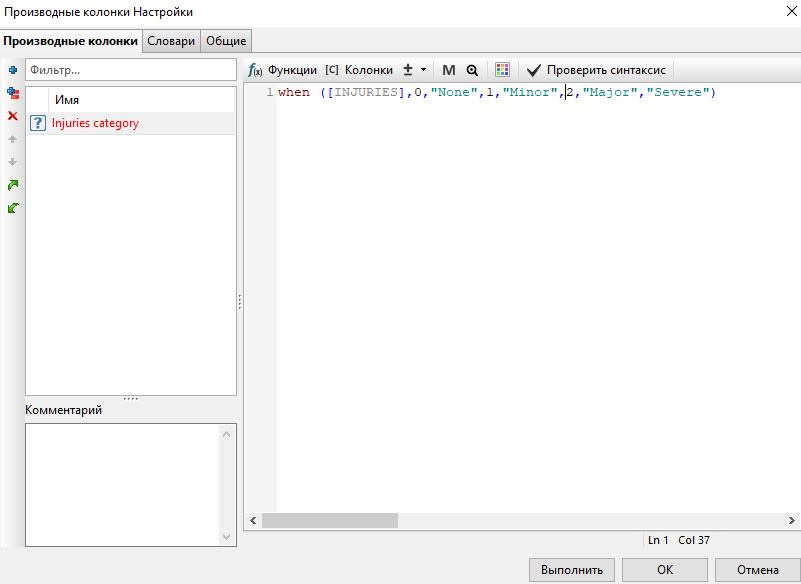
На вкладке Производные колонки окна настроек узла нажмите на кнопку Добавить, введите название новой колонки (Injuries Category) и выражение в поле справа. Нажмите Проверить синтаксис:
Узел определит тип данных в новой колонке.
Разбор выражения
Выражение с when проверяет, выполняется ли условие, и создает значения на основе этого условия.
Пример выражения:
When(Condition,condition=value1,replacement1,value2,replacement2… else final_replacement).
Приведенное выше выражение буквально означает следующее: оценить колонку INJURIES; когда INJURIES=0, заменить значением "None"; когда INJURIES=1, использовать значение "Minor"; когда INJURIES=2 или 3, использовать значение "Major", в других случаях использовать значение "Severe".
Агрегирование данных
Узел Агрегирование выполняет операции со значениями колонок, используя дополнительные измерения (функции агрегирования). Примеры функций: сумма, среднее, медиана, количество, количество уникальных значений, и др.
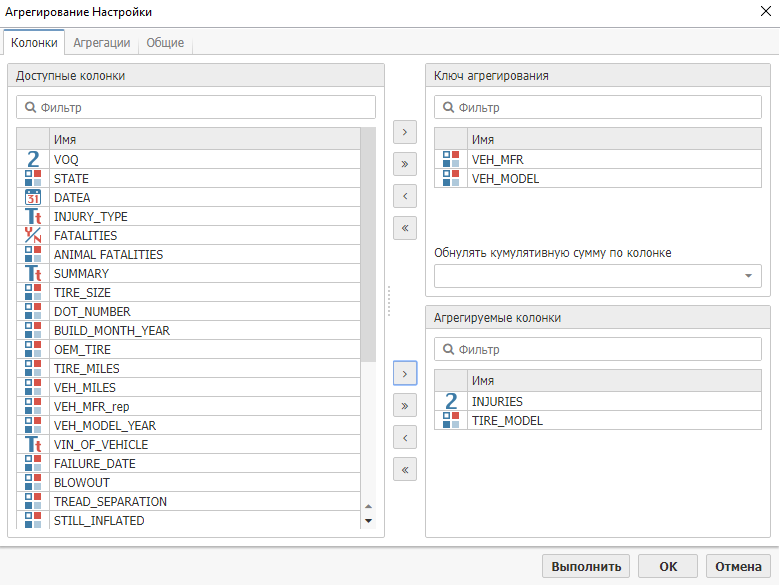
Выберите колонки Injuries и Tire Model в качестве Агрегируемых колонок, а колонки VEH_MFR и VEH_Model в качестве Ключа агрегирования.
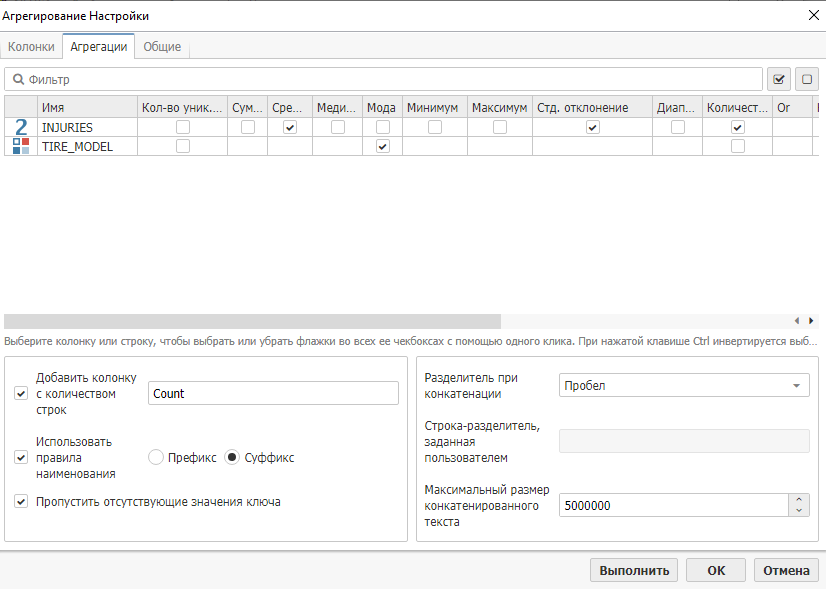
На вкладке Агрегации выберите функции Среднее, Мода, Стандартное отклонение и Кол-во значений, а также включите опцию Добавить колонку с количеством строк, как показано на рисунке ниже:
Выполните узел Агрегирование и просмотрите его результаты.
Использование регулярных выражений в узлах PolyAnalyst
Вводная информация о регулярных выражениях представлена в специальном разделе данного руководства.
Соедините узел Извлечение терминов с узлом Замена категорий на скрипте.
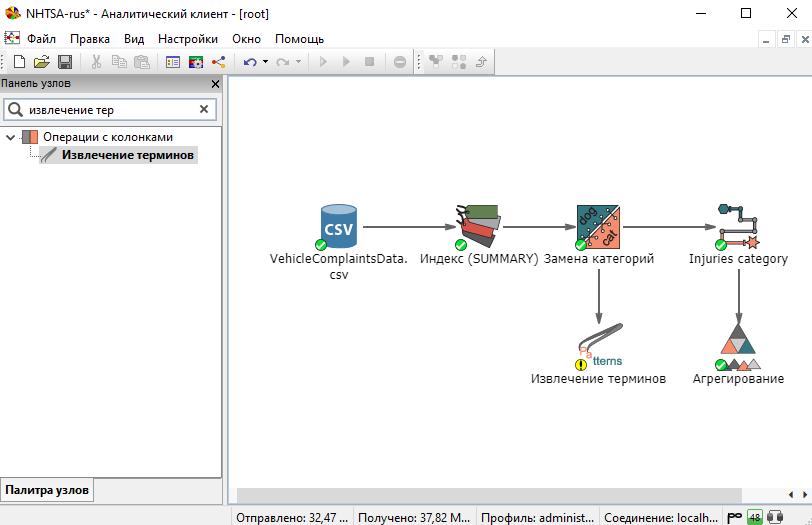
Откройте окно Настройки узла Извлечение терминов. На вкладке Выбор колонок колонка Summary автоматически будет перемещена в поле справа.
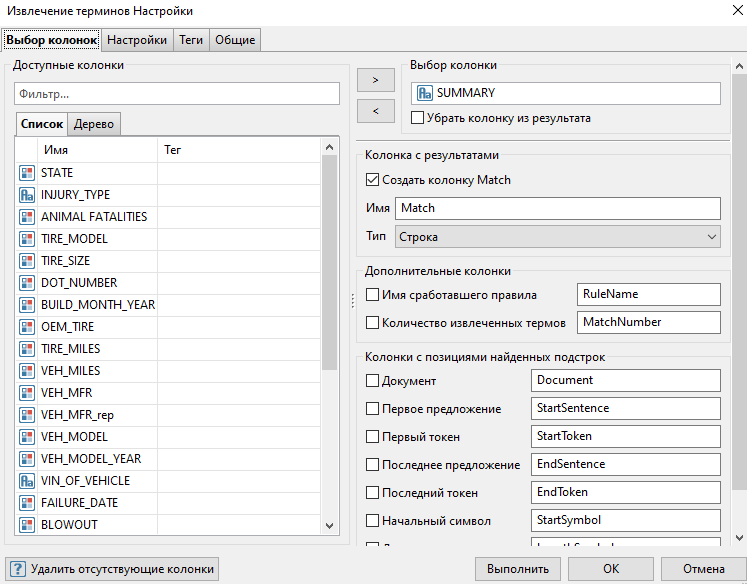
На вкладке Настройки нажмите на кнопку [+] и назовите правило Extract Speed.
В поле Регулярное выражение для поиска соответствий введите следующее выражение:
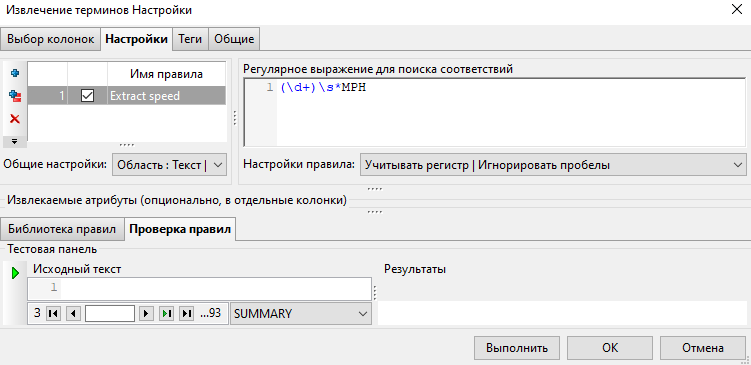
В поле Извлекаемые атрибуты нажмите [+] и добавьте атрибут MPH. В колонке Тип выберите Целое число, в поле Выражение введите $1.
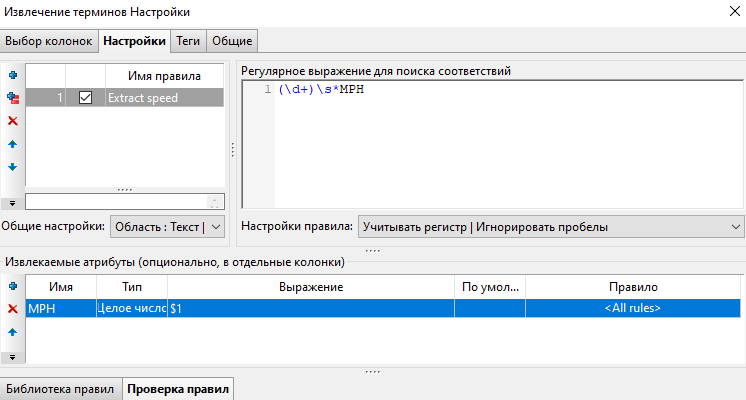
Нажмите Выполнить.
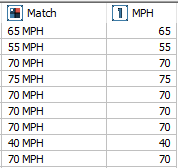
Дважды нажмите на узел Извлечение терминов, чтобы просмотреть его результаты. Используйте полосу прокрутки, чтобы просмотреть две крайние колонки таблицы справа - Match и MPH.
Разбор выражения
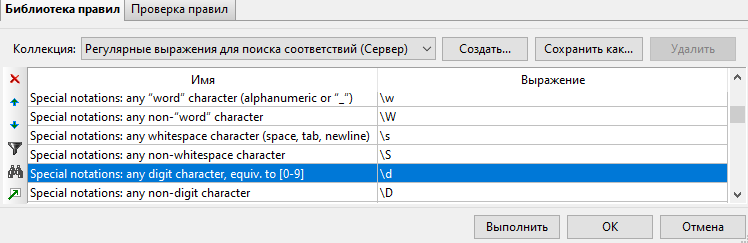
В нижней части вкладки Настройки в окне свойств узла Извлечение терминов имеется Библиотека правил, в которой приводятся толкования значений регулярных выражений. На скриншоте ниже выбрано описание выражения "\d".
Теперь давайте разберем значение выражения "(\d+)\s*MPH". Оно означает, что узел ищет один или несколько числовых символов, за которыми может следовать пробел/несколько пробелов, или пробел отсутствует, и завершается искомая комбинация сочетанием символов MPH. В поле Извлекаемые атрибуты "$1" означает, что узел будет извлекать результат выражения из первых скобок. В нашем случае в первых скобках содержится комбинация "\d+", поэтому в колонку MPH попадут все числа, обнаруженные узлом в подобных сочетаниях.
Замена терминов
Соедините узел Замена терминов с узлом Производные колонки.
Откройте окно настроек узла и выберите колонку Summary на первой вкладке. Включите опцию Исключить источник.
На вкладке Настройки нажмите на кнопку [+], введите выражения в поля Поисковое выражение и Замена, а также введите настройки правила, как показано на скриншоте ниже:
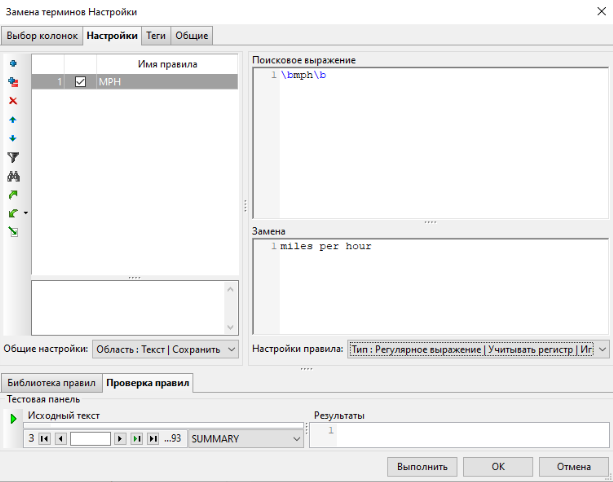
Нажмите Выполнить.
Разбор выражения
Комбинация "\b" в регулярных выражениях обозначает границу слова. Если сочетание символов mph с обеих сторон ограничить знаками границы слова, это будет гарантией того, что mph будет рассматриваться как самостоятельное слово, а не как фрагмент другого слова. Поэтому такое выражение находит фразы типа 55 mph, а слово triumph не отвечает условиям поиска.
Модификация колонок
Соедините узел Модификация колонок с узлом Замена терминов. Узел Модификация колонок позволяет переименовывать колонки, менять их порядок, тип данных в них или исключать колонки из таблицы.
Переместите колонки Summary и Injury_Type в верхнюю часть таблицы.
Выполните узел и просмотрите его результаты. Порядок колонок в выходной таблице узла изменится: колонки Summary и Injury_Type будут отображаться в начале таблицы.
Проверка и исправление орфографических ошибок
Выберите узел Проверка орфографии из раздела Текстовый анализ, перетащите его на скрипт и соедините с узлом Модификация колонок.
В окне настроек узла выберите текстовую колонку Summary. Выполните узел.
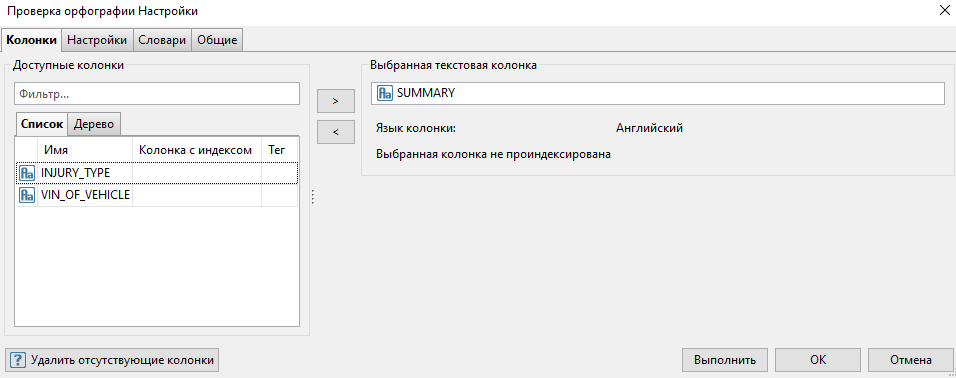
Узел Проверка орфографии автоматически найдет в тексте неправильно написанные слова и предложит варианты их исправления.
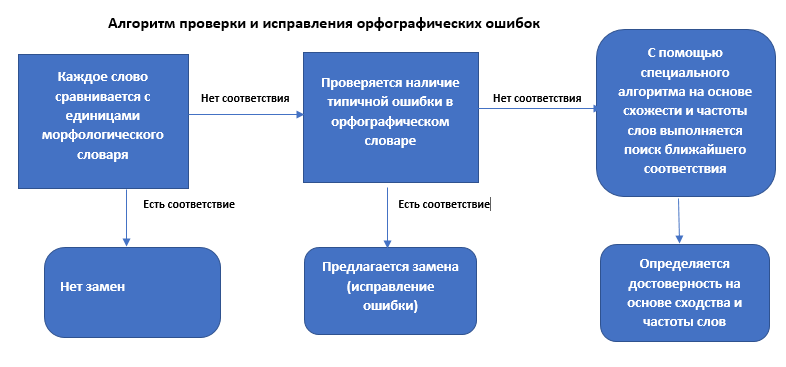
Как узел Проверка орфографии находит ошибки и варианты их исправления
Выявление ошибок и поиск вариантов их исправления происходит в несколько этапов.
Прежде всего, каждое слово сравнивается со словами морфологического словаря. Если какое-то слово не имеет соответствия в словаре, считается, что в нем имеется орфографическая ошибка. Все подобные слова пропускаются через орфографический словарь для того, чтобы найти подходящий вариант замены (исправления ошибки).
Если вариант найден, слово с орфографической ошибкой в результатах узла Проверка орфографии будет выделено синим шрифтом, и значение достоверности для этого слова будет равно 100. Также в таблице будет отображено предлагаемое узлом исправление ошибки.
Если совпадение в орфографическом словаре не будет обнаружено, с помощью специального алгоритма PolyAnalyst попытается определить правильное написание слова. Он также сравнит все слова со словами из морфологического словаря, а затем предложит ближайшее соответствие. Слова, которых не оказалось в орфографическом словаре, будут оформлены черным или серым шрифтом, в зависимости от уровня и заданного порога достоверности. Черный шрифт означает, что уровень достоверности предлагаемого исправления выше заданного порога, и исправление будет выполнено после того, как вы создадите узел с заменами. Исправления, оформленные серым шрифтом, использованы не будут.
Морфологический словарь - это список слов, в котором приводится их корректное написание, а также указывается часть речи слов. Он похож на Оксфордский словарь английского языка, где для каждого слова приводятся возможные частеречные значения. Например, слово bill в словаре будет значиться и как существительное, и как глагол.
Орфографический словарь - это список наиболее часто встречающихся орфографических ошибок и их исправлений. Например, seperate - часто встречающееся неправильное написание слова separate. Оба слова приводятся в словаре.
Значение подсветки в результатах узла Проверка орфографии:
-
Слова, выделенные синим, - известные слова, в которых допущена орфографическая ошибка, согласно используемому орфографическому словарю.
-
Слова, выделенные черным, - слова, в которых, возможно, допущена ошибка, и достоверность ошибки выше заданного порога.
-
Слова, выделенные серым, - слова, в которых, возможно, допущена ошибка, но достоверность ошибки ниже заданного порога.
Редактирование словаря с целью улучшить результаты работы узла Проверка орфографии
Наш узел Проверка орфографии автоматически создал список возможных орфографических ошибок и их предполагаемых замен. Далее потребуются некоторые дополнительные действия со стороны пользователей. Два аспекта работы узла Проверка орфографии настраиваются вручную. Первый - добавление в морфологический словарь слов, которые не должны рассматриваться как ошибки. Второй - добавление пар "ошибка-исправление" в орфографический словарь.
Прежде чем приступить к редактированию словарей, обратите внимание на следующую рекомендацию: вместо того, чтобы редактировать словари, используемые по умолчанию, рекомендуем вам создать собственные словари. Если вы внесете изменения в словари по умолчанию, эти изменения будут применены ко всем проектам, в которых используются данные словари. В дополнение к словарям, используемым по умолчанию, рекомендуется создавать специальные словари под каждый проект.
В целом, вы можете придерживаться следующей стратегии:
-
Просмотрите слова, выделенные синим, чтобы проверить, нет ли там неправильных исправлений. Если таковые будут найдены, исправьте словарную статью в орфографическом словаре, выбрав корректное исправление.
-
Просмотрите слова, выделенные черным, чтобы проверить, нет ли там неправильных замен. Если таковые будут найдены, добавьте словарную статью с правильным написанием таких слов в орфографический словарь.
-
Просмотрите слова, выделенные серым, чтобы проверить, нет ли там правильных исправлений. Если таковые будут найдены, добавьте их в орфографический словарь.
Помните, что в словарь в первую очередь нужно добавлять такие слова, в которых часто допускаются ошибки. Исправление ошибки, которая допущена 20 раз, - важнее, чем исправление орфографической ошибки, которая встречается лишь один раз.
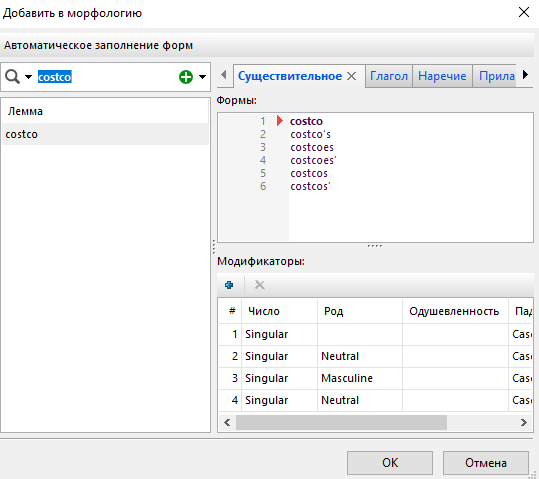
Первый способ добавления слова в морфологический словарь - нажать на слово в результатах узла правой кнопкой мыши, выбрать Добавить в словари, затем выбрать морфологический словарь.
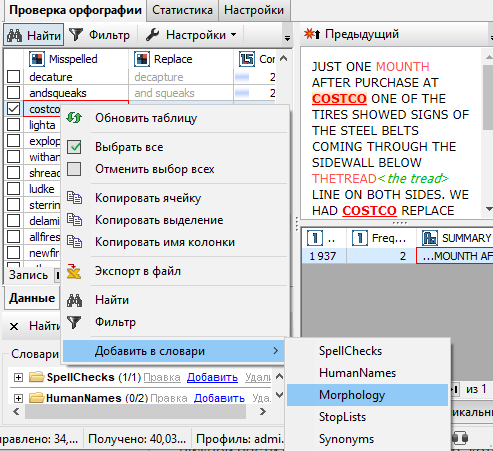
Второй способ предполагает открытие папки морфологического словаря в нижней части экрана. Выберите слово, которое вы хотите добавить в морфологический словарь, а затем нажмите на кнопку Добавить на панели словарей, как показано на скриншоте ниже:
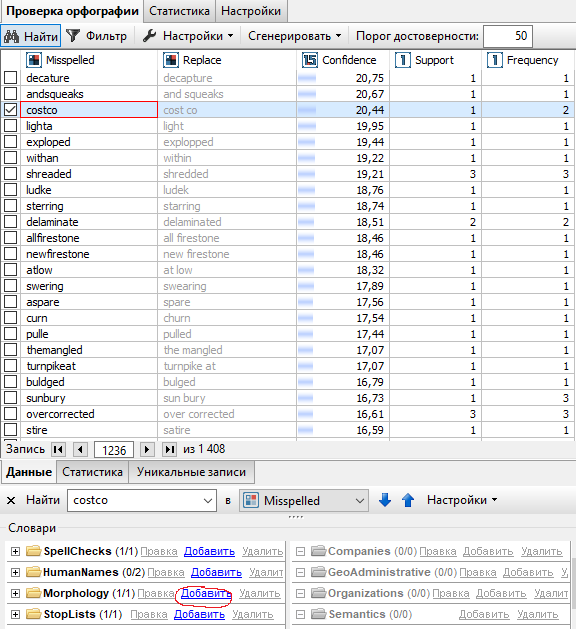
Независимо от выбранного способа редактирования морфологического словаря, откроется новое диалоговое окно, в котором вы сможете отредактировать формы слова и его атрибуты. Нажмите OK.
В результате добавленное в словарь слово в результатах узла Проверка орфографии будет выделено красным цветом, а предложенное исправление исчезнет.
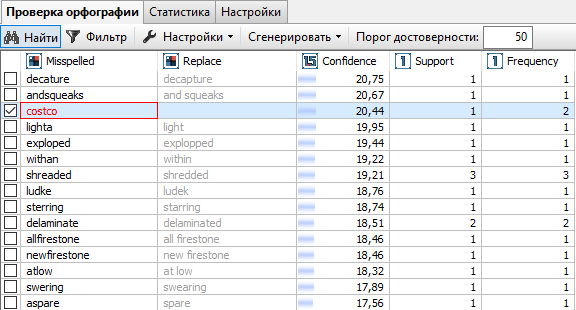
Благодаря этим действиям мы внесли слово Costco, которое является наименованием компании, в морфологический словарь, используемый узлом по умолчанию. Если мы заново выполним узел Проверка орфографии, данное слово не отобразится в списке ошибок и их исправлений. Алгоритм больше не будет считать, что оно написано неправильно.
Далее рассмотрим, как внести изменения в предлагаемые исправления. Это можно сделать путем добавления словарных статей в используемый узлом орфографический словарь, или отредактировав существующие в словаре статьи.
Чтобы добавить словарную статью в орфографический словарь, выберите пару ошибка-исправление и нажмите на кнопку Добавить рядом с орфографическим словарем в нижней левой части окна.
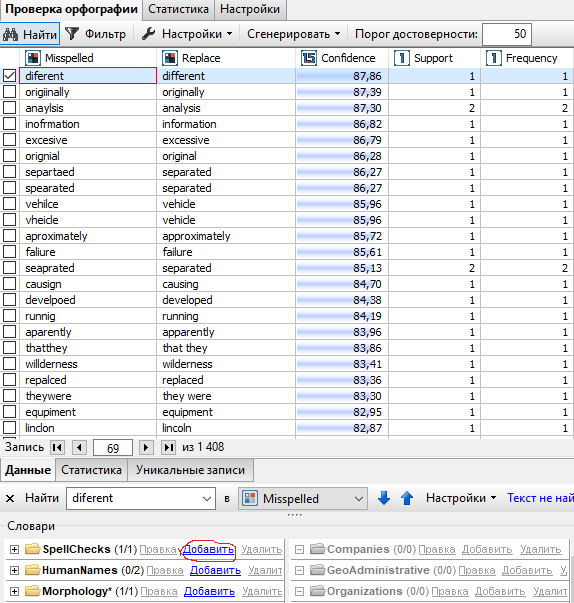
Аналогичный результат можно получить, если выбрать пару ошибка-исправление, нажать на нее правой кнопкой мыши и выбрать опцию Добавить в словари в контекстном меню. Далее необходимо выбрать словарь (Орфография):
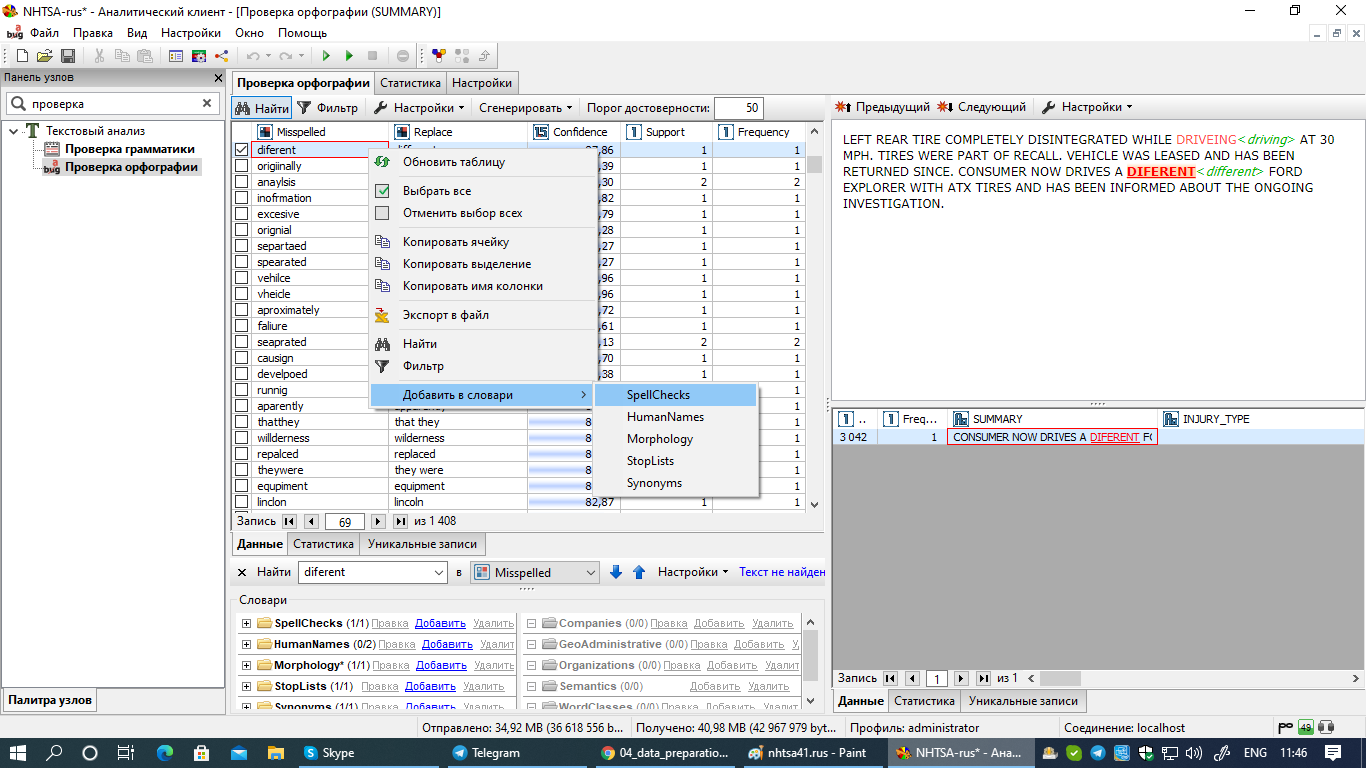
В обоих случаях при этом откроется новое диалоговое окно, в котором вы сможете отредактировать замену найденной ошибке. После того, как вы нажмете OK, пара ошибка-исправление будет добавлена в используемый в проекте орфографический словарь.
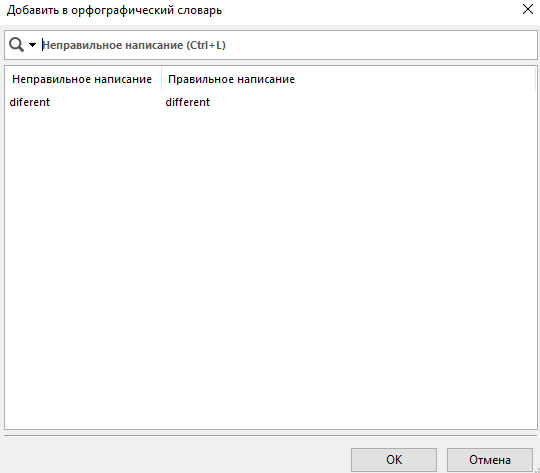
Чтобы отредактировать существующую в орфографическом словаре статью, выберите предлагаемую замену и дважды нажмите на нее, чтобы открыть выпадающее меню. Если выбрать из этого меню другую замену, она будет добавлена в используемый в проекте орфографический словарь. В поле замены после двойного клика вы можете также ввести свой вариант написания слова.
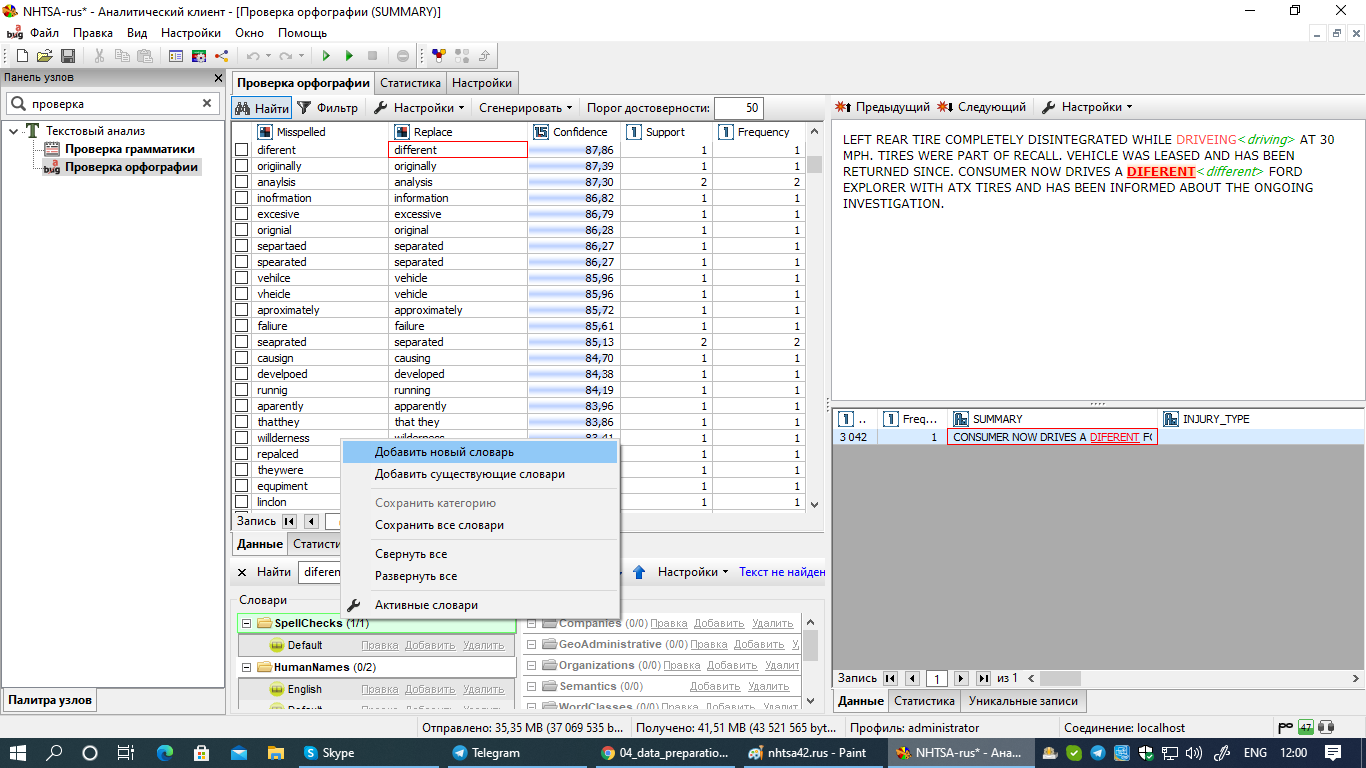
Из окна просмотра результатов узла Проверка орфографии вы можете создавать новые словари.
Так, например, если вы хотите создать новый орфографический словарь, нажмите правой кнопкой мыши на нужную категорию словарей в левом нижнем поле вкладки и выберите опцию Добавить новый словарь в контекстном меню:
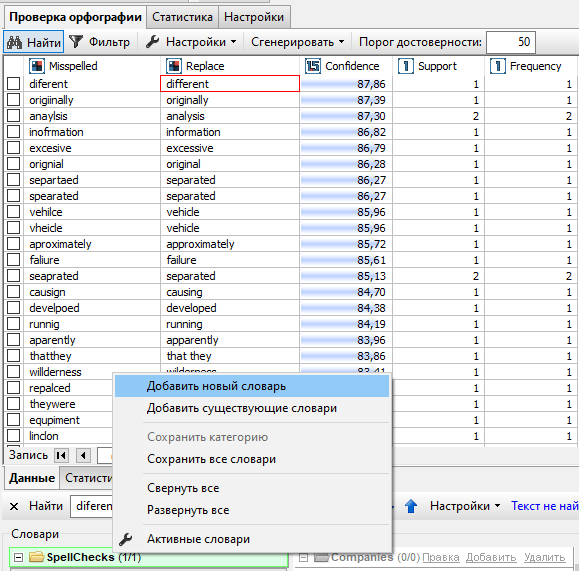
В открывшемся окне введите название и описание нового словаря и укажите его статус - проектный или серверный словарь. Нажмите ОК, чтобы завершить действие:
Этот новый словарь автоматически добавляется к словарям, которые проверяет данный узел во время выполнения.
Словари можно также создавать и редактировать с помощью Менеджера словарей, который открывается из меню Файл (Файл → Управление словарями), либо с помощью сочетания клавиш Ctrl+D.
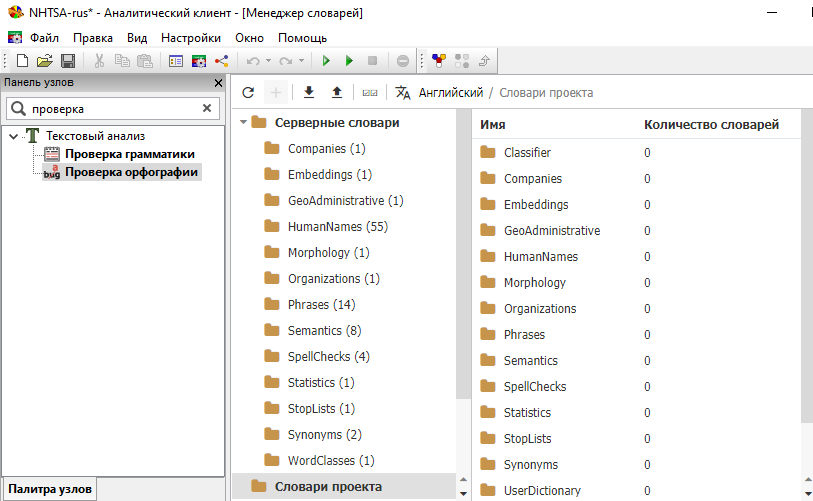
Все возможности использования менеджера словарей описаны в разделе Работа со словарями.
Обратите внимание на то, что при создании нового словаря через окно управления словарями, вам необходимо выбрать этот словарь на этапе настройки узла Проверка орфографии, если хотите, чтобы узел в ходе выполнения использовал именно этот новый словарь.
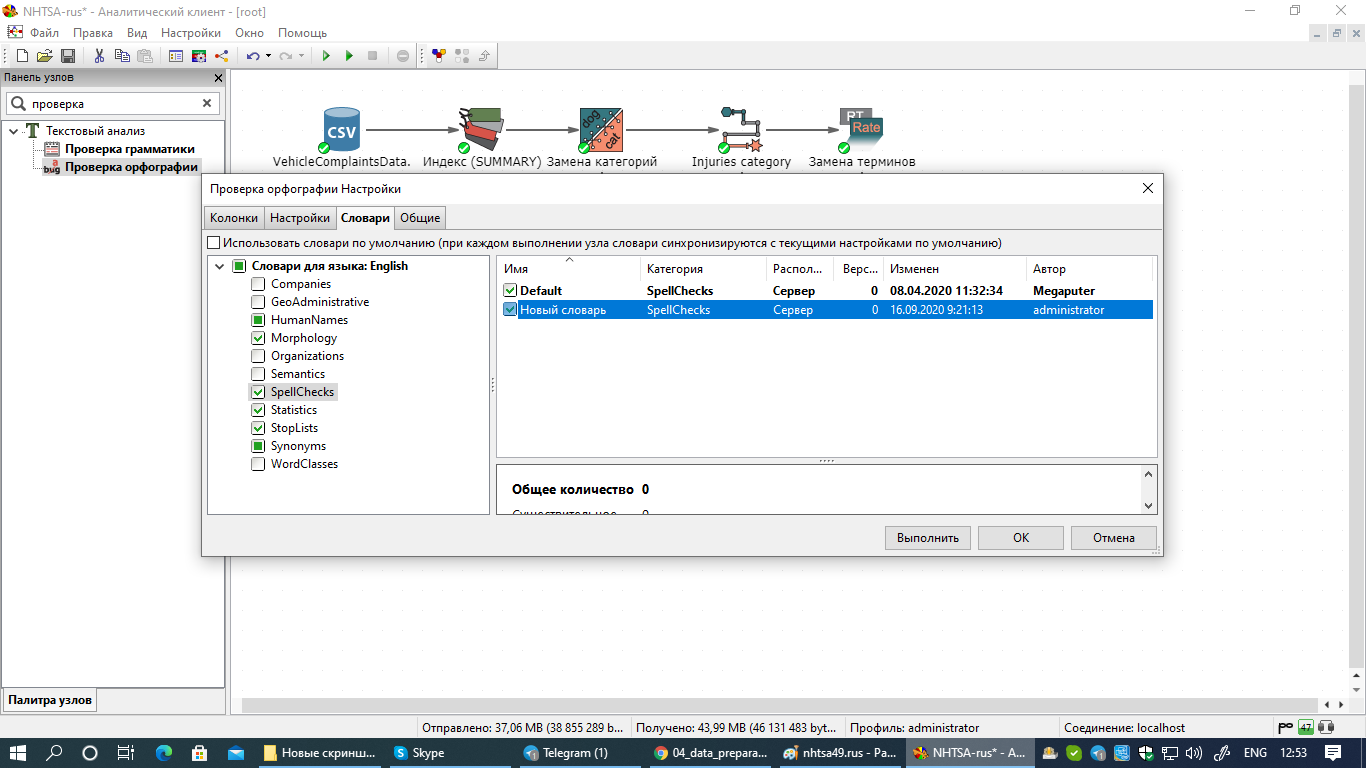
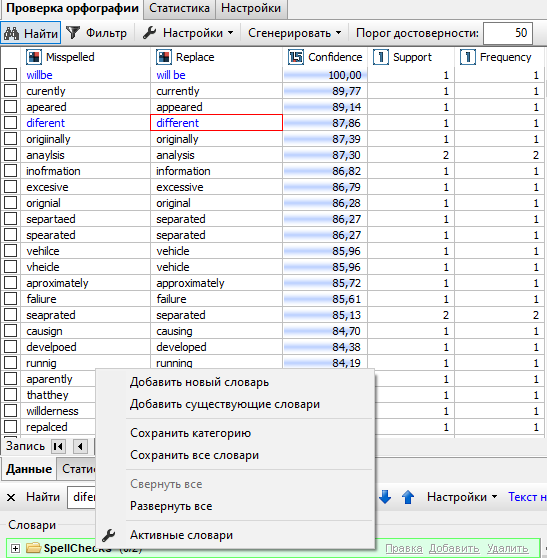
Для того, чтобы сохранить изменения, внесенные вами в словари через окно просмотра результатов узла Проверка орфографии, нажмите правой кнопкой мыши в любом месте в поле Словари, затем выберите опцию Сохранить (отдельную категорию словарей или все словари).
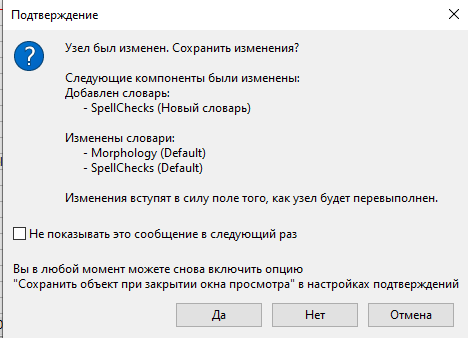
Если вы попытаетесь закрыть окно, не сохранив изменения, на экране появится напоминание об этом.
Замена слов с орфографическими ошибками
Выберите опцию Показать в контекстном меню узла Проверка орфографии, чтобы открыть окно просмотра результатов. Нажмите Сгенерировать и выберите Замены.
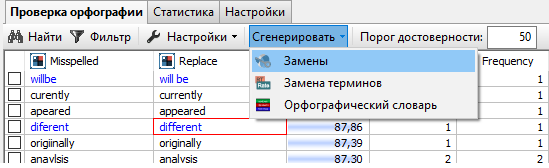
Откроется окно для ввода имени нового узла. Введите имя и нажмите Ок, чтобы завершить действие. Новый узел будет автоматически добавлен на скрипт и настроен.
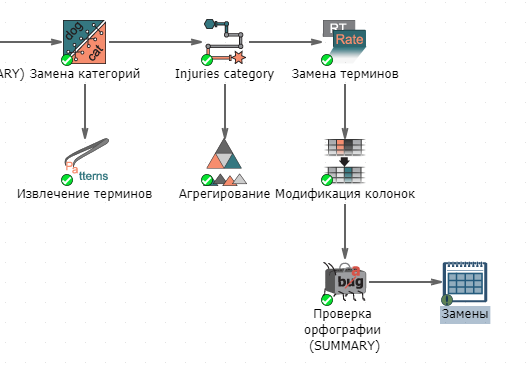
Выполните узел. Используя настройки, заданные по умолчанию, узел сгенерирует таблицу данных, в которой все распознанные орфографические ошибки в текстовой колонке будут исправлены.
Настройки исправления ошибок
Существует 4 способа исправления ошибок, каждый из которых имеет свои достоинства и недостатки. Самый простой способ - создание узла Замены. Однако рассмотрим все возможные способы исправления ошибок.
Разметка текста
Выберите узел Разметка текста из раздела Текстовый анализ в палитре узлов, перетащите его на скрипт и соедините с узлом Замены.
На вкладке Колонки узла Разметка текста выберите колонку Summary в качестве независимой колонки.
На вкладке Настройки выберите Парсер на основе грамматики зависимостей.
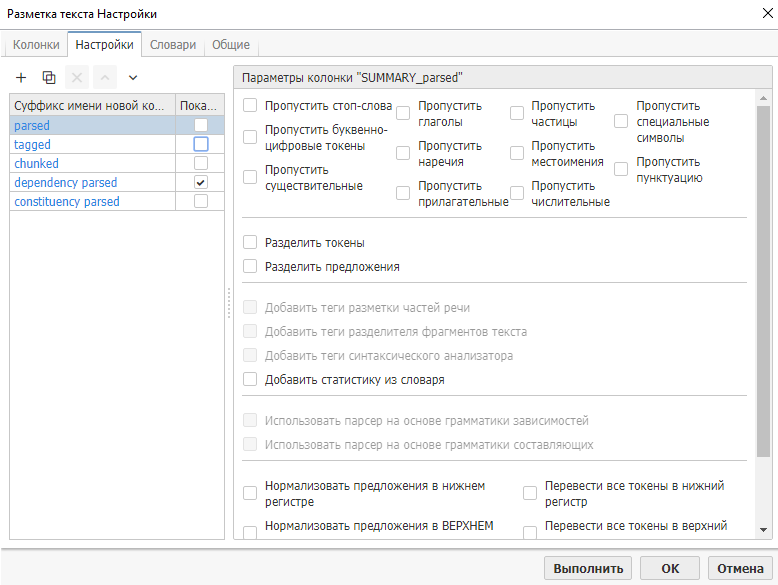
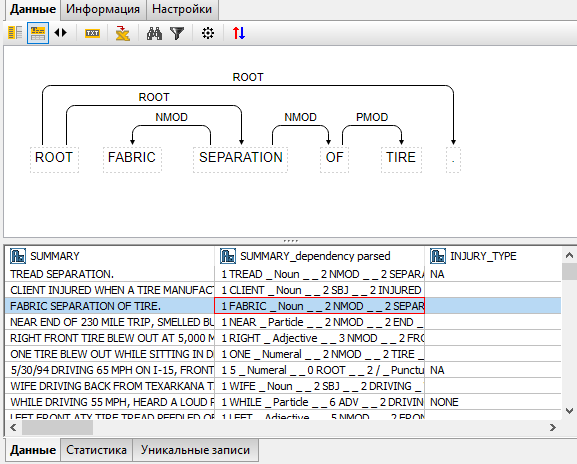
Выполните узел и просмотрите его результаты.
Парсер на основе грамматики зависимостей представляет предложение в виде диаграммы, где отображаются отношения между словами. Позже мы сможем использовать эти отношения между словами при создании модели классификации текста.
Анонимизация личной информации
Таблица с жалобами, поступившими в NHTSA, содержит открытые данные. Чаще всего в ходе выполнения аналитического проекта приходится иметь дело с личными данными, которые необходимо анонимизировать. В системе PolyAnalyst есть несколько инструментов, которые позволяют это делать.
Добавьте новый узел Извлечение сущностей на скрипт. Соедините его с ранее созданным узлом Замены.
На вкладке Колонки выберите колонку Summary в качестве рабочей текстовой колонки узла. На вкладке Сущности отключите стандартные сущности (снимите флажок с чекбокса Standard в колонке Включить), затем выберите сущности People и Identifiers.
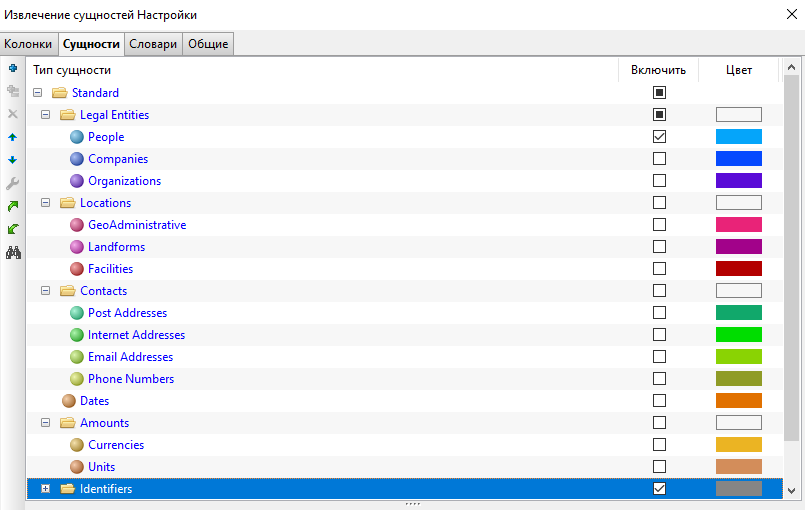
Выполните узел и просмотрите его результаты.
Выберите узел Анонимизация сущностей из раздела Текстовый анализ и соедините его с узлом Извлечение сущностей.
На вкладке Настройки выберите People в списке сущностей слева и Заменить шифром - справа.
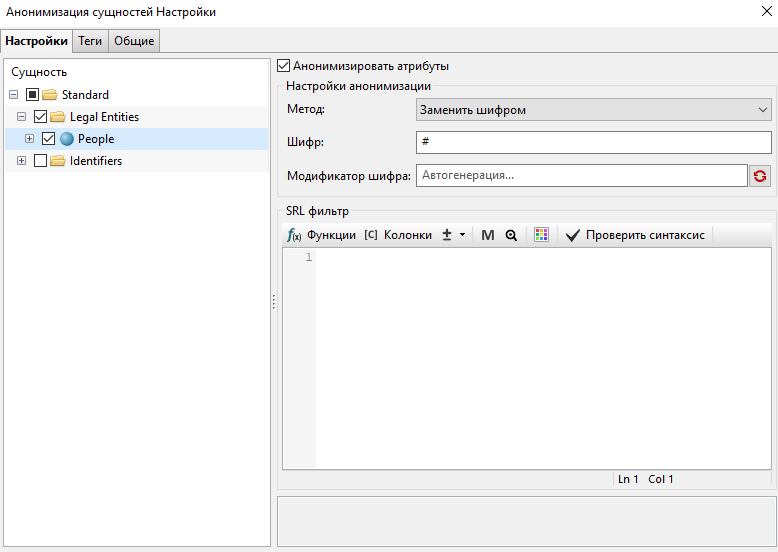
Выполните узел и просмотрите его результаты. Узел создаст новую колонку под названием Summary_anonymized, в которой имена людей будут заменены шифром.
Данная операция завершает этап подготовки данных. Теперь данные готовы к анализу.