Функции нормализации
Нормализация формы слова
Функция normalize() используется для приведения словоформы к лексеме, то есть к такому написанию слова, которое обычно встречается в словаре. Так, глаголы приводятся к инфинитиву («работает», «работая» ⇒ «работать»), а существительные к именительному падежу единственного числа («компаний», «компанией» ⇒ «компания»).
Синтаксис
Примечание: У функции normalize() есть синонимичная ей функция norm(), которая выдает аналогичный результат.
Аргументы
Функция принимает один аргумент, — это то значение, которое необходимо отформатировать.
Функция полезна для объединения разных словоформ в одну лексему.
Пример
Правило на Изображении 1 извлекает фразу «развивающаяся экономика» во всех формах и выдает результат с нормализацией и без нее.
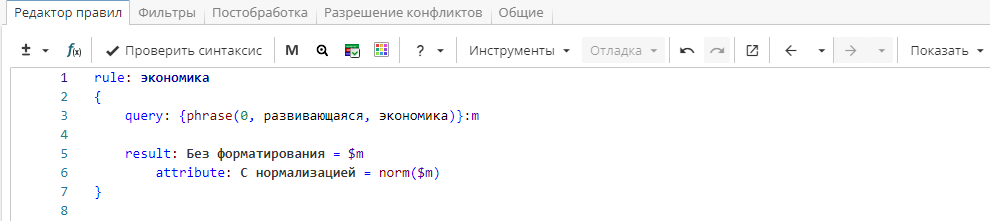
Изображение 2 показывает результаты правила в отчете узла «Извлечение сущностей».

Нормализация упоминаний сущности
В тексте одна и та же сущность может быть представлена различными вариантами. Например, «Иванов Иван Иванович» может упоминаться в тексте как «Иван», «Иванов И.», «Иван Иванов» и т.д., а «Сбербанк» и «Сбербанк России» — это варианты названия компании «ПАО «Сбербанк»».
Функция toentity() приводит варианты написания сущности к стандартному имени сущности, которое определяется узлом «Извлечение сущностей». Эта функция полезна, когда XPDL-правила ссылаются на ранее найденные сущности.
Пример. Информация о сделках компаний
На Изображении 3 показан проект, где находится информация о приобретениях компаний. Первый узел «Извлечение сущностей» находит так называемые «Стандартные сущности», к которым относятся, например, имена людей, компании или почтовые адреса. Пользовательская сущность «Приобретение» во втором узле находит информацию о покупке компаний.
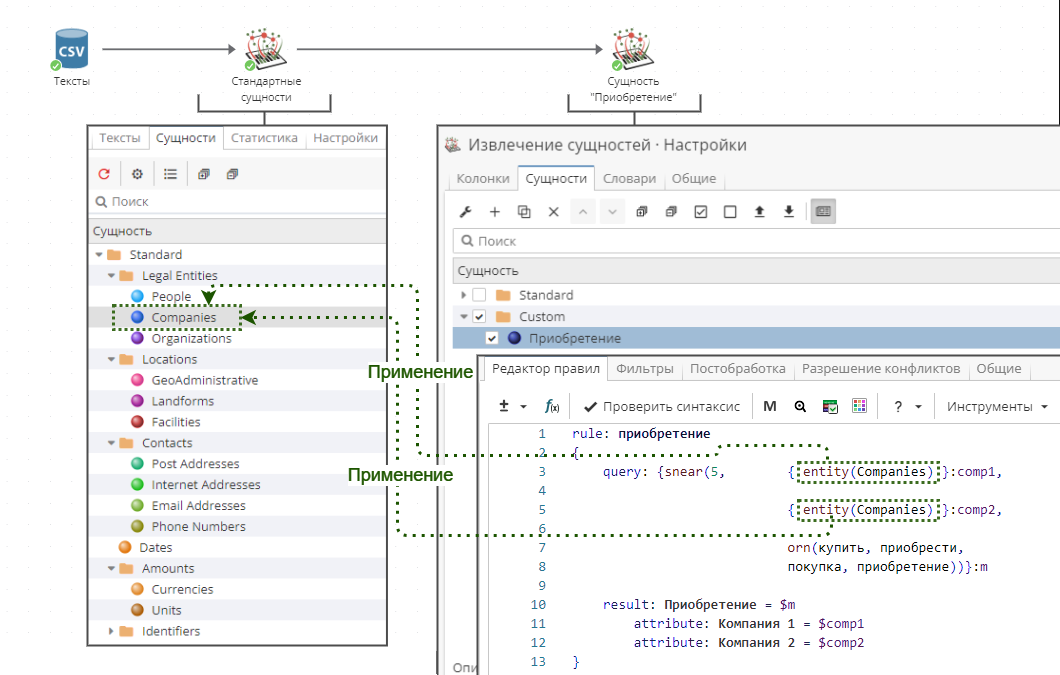
Обратите внимание, что в правиле «acquisition» используется PDL-функция entity(), которая позволяет использовать уже найденные сущности (имена компаний). Таким образом их не приходится извлекать заново. Это одно из преимуществ предварительного выполнения узла «Извлечение сущностей».
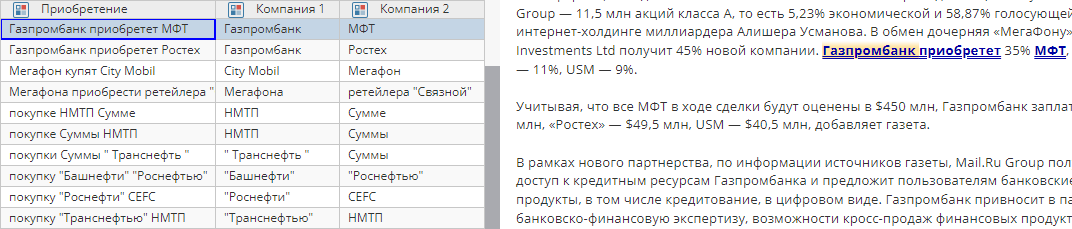
Как видно на Изображении 4, правило выдает относительно точные результаты («Газпромбанк приобретет МФТ», «покупку "Транснефтью" Суммы»), но есть недочеты в формате результата: мы видим варианты написания компаний, а не стандартный вариант. Например, «МФТ» или «НМПТ» — это аббревиатуры компаний, а «Транснефтью» и «Транснефть» выглядят так, как будто это разные компании.
Так происходит, потому что по умолчанию XPDL выводит результаты в том виде, в каком они представлены в тексте. Эту проблему можно решить при помощи функции toentity(), которая заменяет варианты имени сущности стандартным именем, присвоенным ей узлом «Извлечение сущностей». Измененное правило представлено на Изображении 5.
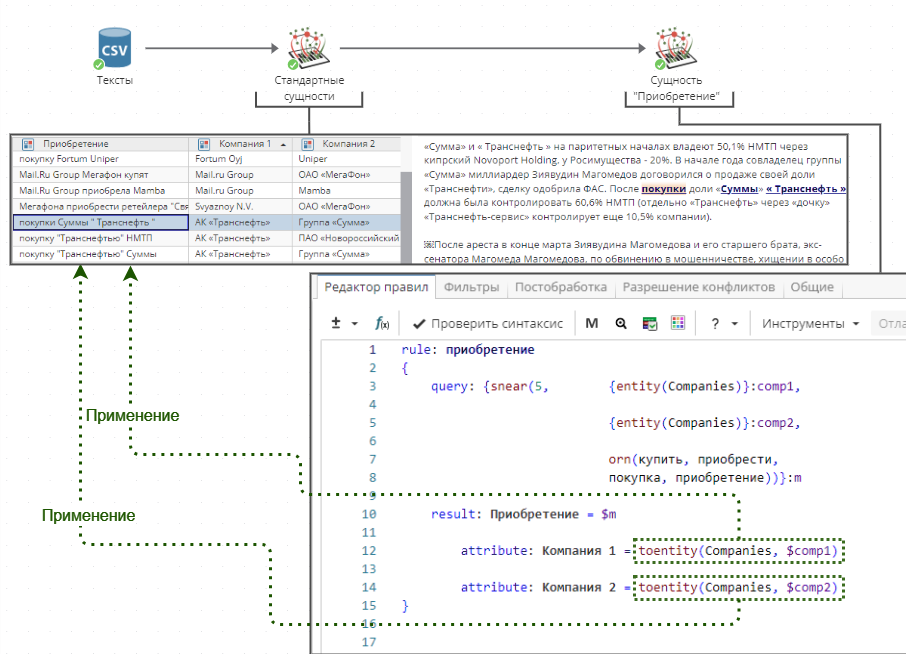
Изображение 6 показывает результаты правил в отчете узла «Извлечение сущностей».

Функция также поддерживает опциональный параметр field, который преобразует аргумент в заданный атрибут сущности.
Примечание: Функция toentity() не отработает, если аргумент не ссылается на извлеченную сущность. В этом случае значение атрибута останется без изменений.
Если название сущности или именованного параметра field включает цифры или специальные символы (&, /, и т.п.), то его нужно заключать в кавычки, например: toentity("A&B", $1, field:="A/B")
Опциональный именованный параметр default позволяет указать значение атрибута для случаев, когда привести его к стандартному имени сущности не удалось. Так происходит, если сущность не была посчитана или работает некорректно. Например, toentity(People, $&, default:="").
Объединение синонимов
Функция tosynonym() используется для замены аргумента его опорным словом (доминантой) из словаря синонимов.
Эта функция полезна для объединения синонимов («покупать» - «приобретать», «кидать» - «бросать»), аббревиатур («Соединенные штаты Америки» – «США»), вариантов написания слова («матрас» - «матрац», «баннер» - «банер»), в том числе вариантов дефисного и бездефисного написания слов («фастфуд» - «фаст-фуд»).
Пример. Найти информацию о динамике рынка
Правило на Изображении 7 находит информацию о рыночной динамике. Правило извлекает информацию типа «продажи Ауди падают», «рынок смартфонов растет» или «рынок ипотеки вырос».
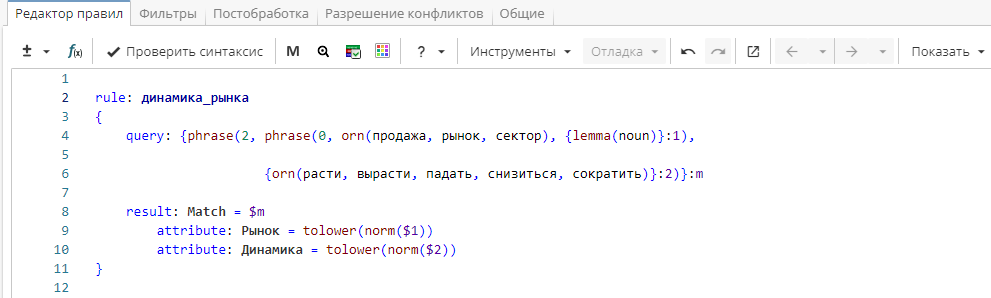
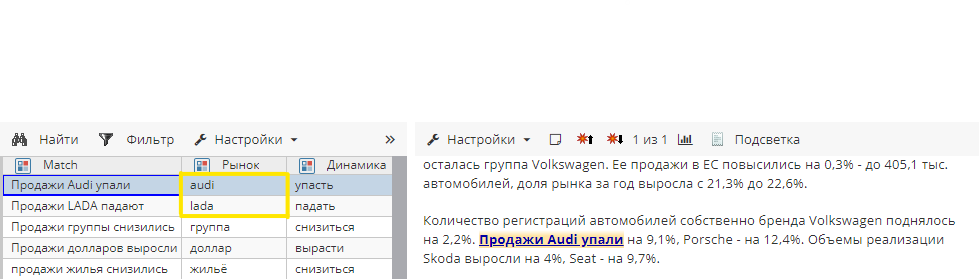
В этом правиле используется базовое форматирование результата. Сначала функция norm() приводит полученные результаты к словарной форме («упали» ⇒ «упасть», «смартфонов» ⇒ «смартфон»). Затем результаты приводятся к строчному регистру с помощью функции tolower(). Изображение 8 показывает результаты правила в отчете узла «Извлечение сущностей».
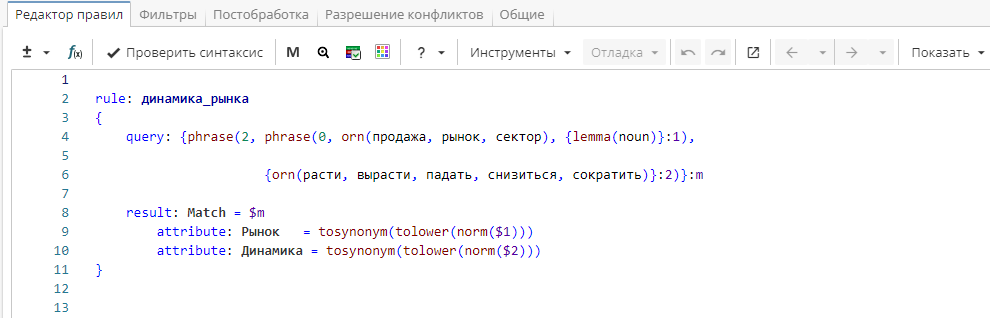
Дальнейшим шагом будет объединение синонимов, в том числе контекстных, или слов, обозначающих похожие понятия, например, «машина» - «автомобиль» - «ауди», «недвижимость» - «жилье». Чтобы сократить вариативность данных и упростить дальнейший анализ, можно использовать функцию tosynonym(), как показано на Изображении 9.
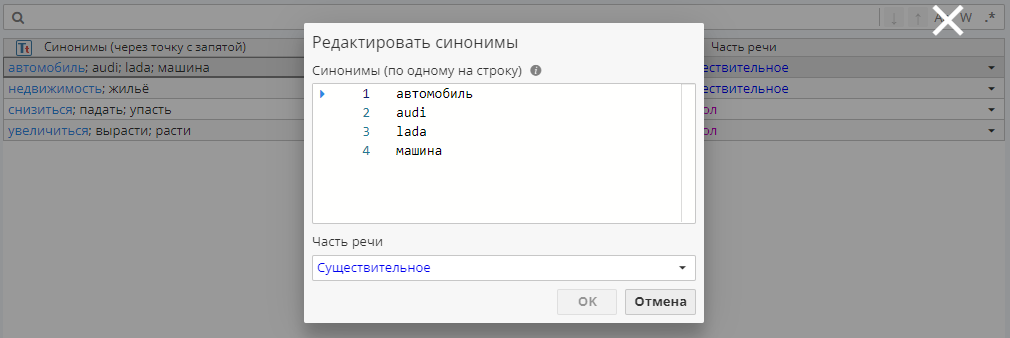
Эта функция заменяет аргумент на соответствующее ему опорное слово в словаре синонимов. Если аргумент отсутствует в словаре, пользователю нужно создать новую синонимическую группу, перечислить слова, которые нужно заменить, и выбрать опорное слово, которое представляет группу (оно помечено треугольным маркером), как показано на Изображении. 10.
На Изображении 11 показан обновленный результат. Обратите внимание, что близкие по значению понятия, например, «автомобиль» - «ауди», «увеличиться» - «вырасти» заменены общим синонимом.

Примечания
-
Если аргумент отсутствует в словаре синонимов, значение аргумента останется без изменений.
-
Рекомендуется создавать отдельные словари специализированных синонимов, потому что изменения дефолтного словаря могут повлиять на результаты других алгоритмов текстового анализа, например, на извлечение ключевых слов.
-
Для корректной работы функции необходимо выбрать все необходимые словари в настройках узла.