ПРИЛОЖЕНИЕ
-
Примеры простых XPDL-правил
-
Примеры иерархически организованных XPDL-правил
Пример 1
Правило извлекает значение атмосферного давления в миллиметрах ртутного столба. Правило находит слова и словосочетания «атмосферное давление» или «АД», после которых на расстоянии 20 идет фраза, которая ищет последовательность элементов число, «мм», «рт.», «ст.» на расстоянии «0».
В результат, в колонку «Атмосферное давление», выводится именованная группа «m» и атрибуты «Значение» (именованная группа «value») и «Единица измерения». Последний атрибут имеет постоянное значение «Миллиметр ртутного столба».
XPDL правило
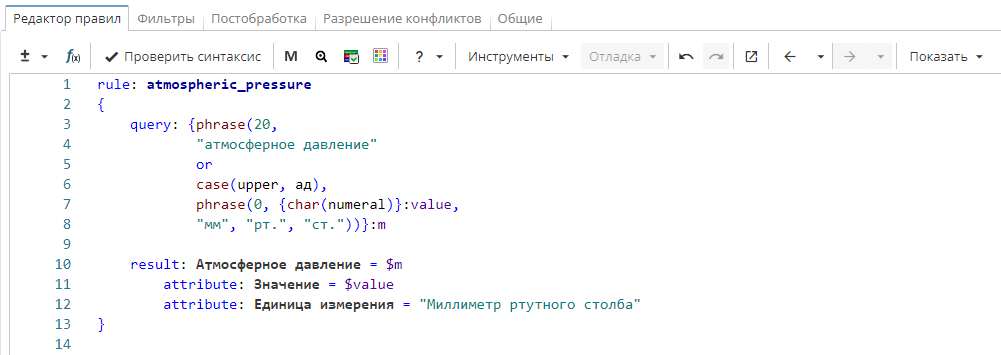
Фрагмент правила
rule: atmospheric_pressure
{
query: {phrase(20,
"атмосферное давление"
or
case(upper, ад),
phrase(0, {char(numeral)}:value,
"мм", "рт.", "ст."))}:m
result: Атмосферное давление = $m
attribute: Значение = $value
attribute: Единица измерения = "Миллиметр ртутного столба"
}Текст
Результат

Пример 2
Правило извлекает международный стандартный серийный номер (ISSN), позволяющий идентифицировать периодические издания. Правило ищет слово «ISSN», после которого идут четыре цифры, дефис, четыре цифры или три цифры и «x».
Номер ISSN образует именную группу «issn» и отображается в колонке «Номер», а атрибуту «Тип» присваивается постоянное значение «ISSN».
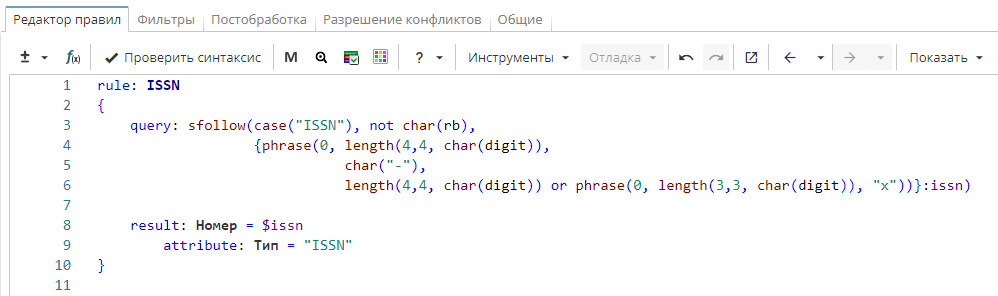
Фрагмент правила
rule: ISSN
{
query: sfollow(case("ISSN"), not char(rb),
{phrase(0, length(4,4, char(digit)),
char("-"),
length(4,4, char(digit)) or phrase(0, length(3,3, char(digit)), "x"))}:issn)
result: Номер = $issn
attribute: Tип = "ISSN"
}Текст
Результат

Пример 3
Правило извлекает названия рек в определенном лексическом контексте. Оно находит ключевые слова «берег», «верховье», «исток», «низовье, «приток», «устье», после которого идет от одного до двух повторений неизвестного морфологическому словарю слова с большой буквы, состоящего из буквенных символов.
В результат в колонку «Match» выводится именованная группа «m» и атрибут «Река» (именованная группа «river»).
XPDL правило
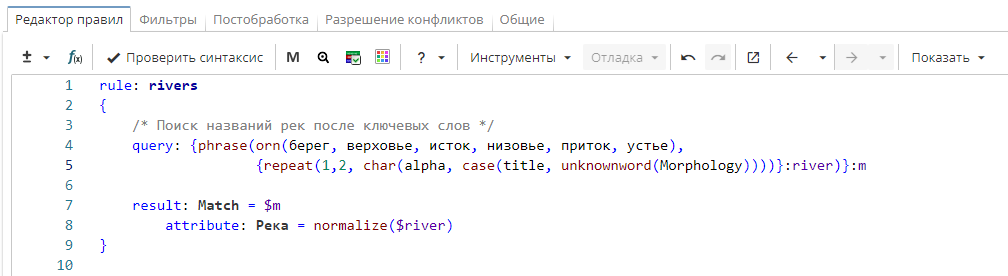
Фрагмент правила
rule: rivers
{
/* Поиск названий рек после ключевых слов */
query: {phrase(orn(берег, верховье, исток, низовье, приток, устье),
{repeat(1,2, char(alpha, case(title, unknownword(Morphology))))}:river)}:m
result: Match = $m
attribute: Peкa = normalize($river)
}Текст
Результат

Пример 4
Правило извлекает положительные и отрицательные отзывы об обслуживании клиентов. Верхнее правило «service_quality» ищет слова «обслуживание» или «обслуживание клиентов». Таким образом, из дальнейшего поиска исключаются тексты, в которых таких слов и словосочетаний не встречается. У этого правила есть два дочерних правила: «positive» и «negative». Правило «positive» находит последовательность, состоящую из позитивного прилагательного (например, «хороший») и того, что нашло родительское правило («обслуживание», «обслуживание клиентов»). В результат идет именованная группа «m» и ее атрибуты «Evaluation» (оценочное прилагательное) и «Object» (объект оценки).
Правило «negative» находит последовательность, состоящую из негативного прилагательного (например, «ужасный») и того, что нашло родительское правило («обслуживание», «обслуживание клиентов»). Как и в сестринском правиле, в результат идет именованная группа «m» и ее атрибуты «Evaluation» (оценочное прилагательное) и «Object» (объект оценки).
XPDL правило
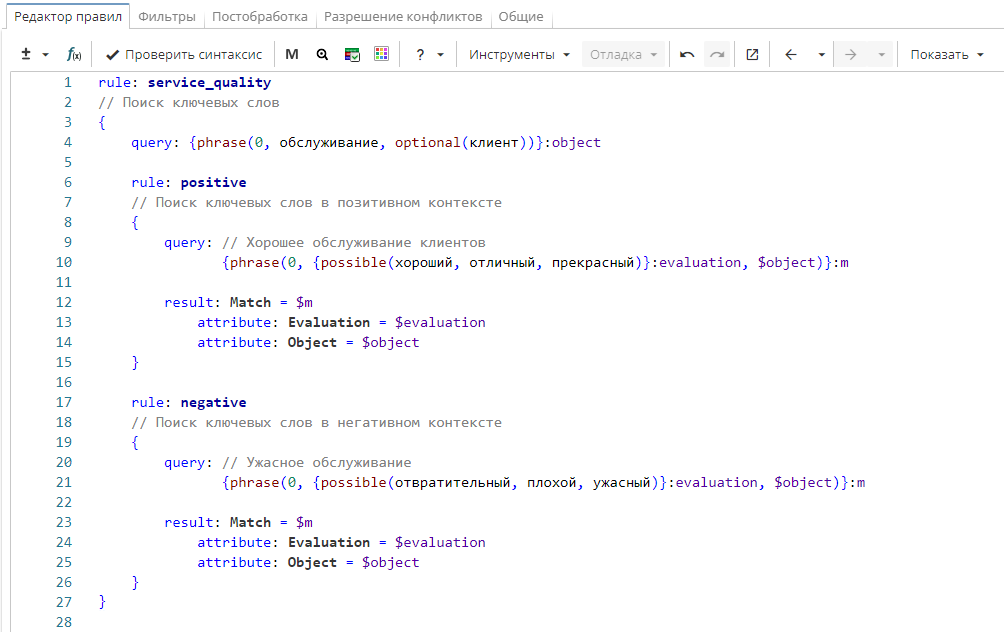
Фрагмент правила
rule: service_quality
// Поиск ключевых слов
{
query: {phrase(0, обслуживание, optional (клиент))}:object
rule: positive
// Поиск ключевых слов в позитивном контексте
{
query: // Хорошее обслуживание клиентов
{phrase(0, {possible(хороший, отличный, прекрасный )}:evaluation, $object)}:m
result: Match = $m
attribute: Evaluation = $evaluation
attribute: Object = $object
}
rule: negative
// Поиск ключевых слов в негативном контексте
{
query: // Ужасное обслуживание
{phrase(0, {possible(отвратительный, плохой, ужасный)}:evaluation, $object)}:m
result: Match = $m
attribute: Evaluation = $evaluation
attribute: Object = $object
}
}Текст
Результат

Пример 5
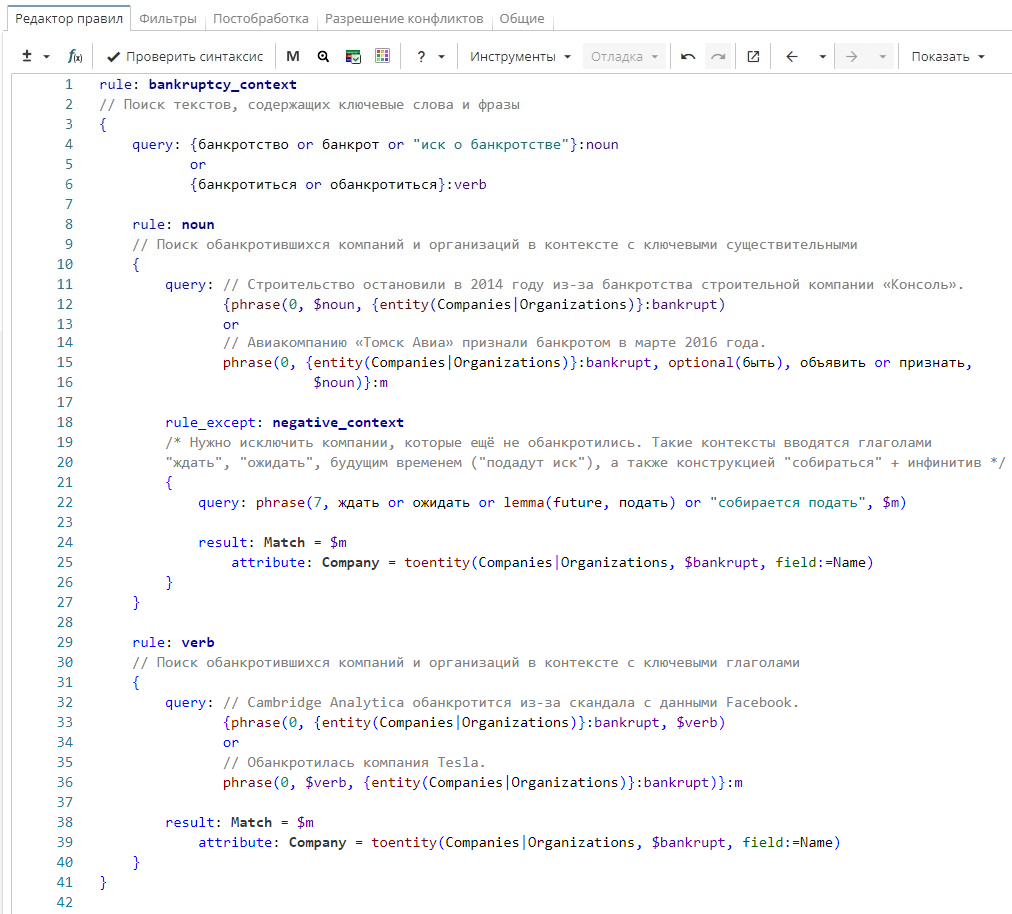
Правило извлекает факты о банкротстве компаний. Поисковый запрос верхнего правила «bankruptcy_context» ищет ключевые слова и фразы, определяющие контекст банкротства. Это могут быть существительные (входят в именованную группу «noun») или глаголы (входят в именованную группу «verb»). Правило работает как фильтр, исключая тексты, которые не имеют отношения к банкротству. Это увеличивает скорость выполнения правил. У верхнего правила есть два дочерних правила: «noun» и «verb».
Правило «noun» ищет компании и организации, которые встречаются в именных контекстах, найденных верхним правилом. У этого правила есть исключающее дочернее правило «negative_context», которое отбрасывает контексты с будущим временем и такими конструкциями, как «собираться + инфинитив», «ждать», «ожидать». То есть те случаи, когда факт банкротства возможен в будущем, но еще не подтвержден. Извлеченный поисковым запросом результат выводится в колонку «Match», а название обанкротившейся компании или организации в качестве атрибута «Company». Как видно на изображении ниже, контексты, исключенные с помощью этого правила, не выводятся в результат.
Правило «verb» ищет компании и организации, которые встречаются в глагольных контекстах, найденных верхним правилом. Извлеченный поисковым запросом результат выводится в колонку «Match», а название обанкротившейся компании или организации в качестве атрибута «Company».
Обратите внимание, что для правильной работы этого правила необходимо наличие выполненного узла «Извлечение сущностей».
XPDL правило
Фрагмент правила
rule: bankruptcy_context
// Поиск текстов, содержащих ключевые слова и фразы
{
query: {банкротство or банкрот or "иск о банкротстве"}:noun
or
{банкротиться or обанкротиться}:verb
rule: noun
// Поиск обанкротившихся компаний и организаций в контексте с ключевыми существительными
{
query: // Строительство остановили в 2014 году из-за банкротства строительной компании «Консоль».
{phrase(0, $noun, {entity(Companies|Organizations) }:bankrupt)
or
// Авиакомпанию «Томск Авиа» признали банкротом в марте 2016 года.
phrase(0, {entity(Companies|Organizations)}:bankrupt, optional (быть), объявить or признать, $noun)}:m
rule_except: negative_context
/* Нужно исключить компании, которые ещё не обанкротились. Такие контексты вводятся глаголами "ждать", "ожидать"
будущим временем ("подадут иск"), а также конструкцией "собираться" + инфинитив */
{
query: phrase(7, ждать or ожидать or lemma(future, подать) or "собирается подать", $m)
result: Match = $m
attribute: Company = toentity(Companies|Organizations, $bankrupt, field:=Name)
}
}
rule: verb
// Поиск обанкротившихся компаний и организаций в контексте с ключевыми глаголами
{
query: // Cambridge Analytica обанкротится из-за скандала с данными Facebook.
{phrase(0, {entity(Companies|Organizations)}:bankrupt, $verb)
or
// Обанкротилась компания Tesla.
phrase(0, $verb, {entity(Companies|Organizations) }:bankrupt)}:m
result: Match = $m
attribute: Company = toentity(Companies|Organizations, $bankrupt, field:=Name)
}
}Текст
Результат

Пример 6
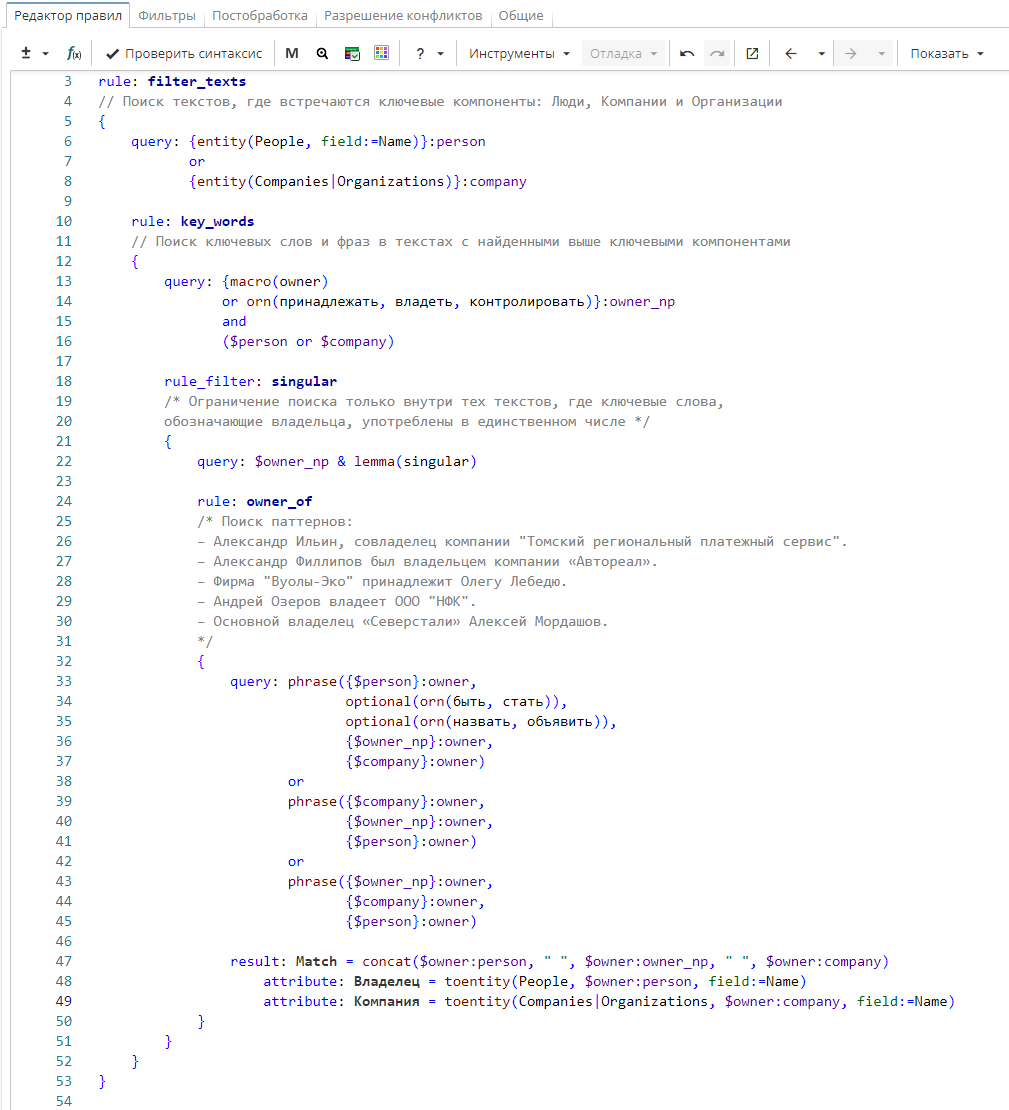
Правило извлекает факт владения компанией или организацией физическим лицом. Поисковый запрос правила «filter_texts» находит тексты, где встречаются участники этого факта: такие сущности, как Люди, Компании и Организации.
У этого правила есть дочернее правило «key_words», которое находит слова и фразы, указывающие на владельца компаний или организаций в текстах, найденных верхним правилом («filter_texts»). Для краткости записи правило вызывает макрос «owner», где перечислены некоторые из этих слов. У правила есть дочернее фильтрующее правило «singular».
Фильтрующее правило «singular» оставляет только те тексты, найденные верхним правилом, где есть существительные и глаголы в единственном числе. У правила есть дочернее правило «owner_of».
Правило «owner_of» описывает варианты шаблонных фраз. Например, за именем человека (именованная группа «person») следуют опциональные аргументы (например, глаголы «быть», «стать», «назвать», «объявить», «владеть», «принадлежать»), слово «владелец» или его синонимы (именованная группа «owner_np»), а затем имя компании (именованная группа «company»). Или же название компании, слово «владеть» или «владелец» и их синонимы, имя человека (например, «Фирма "Вуолы-Эко" принадлежит Олегу Лебедю»). Наконец, слово «владеть» или «владелец» и их синонимы, название компании, имя человека («Основной владелец «Северстали» Алексей Мордашов»).
Правило выводит в качестве результата конкатенированные элементы «person», «owner_np» и «company» как «Match», имя владельца как «Владелец» и название компании как «Компания».
Обратите внимание, что для правильной работы этого правила необходимо предварительно выполнить узел «Извлечение сущностей».
XPDL правило
Фрагмент правила
rule: filter_texts
// Поиск текстов, где встречаются ключевые компоненты: Люди, Компании и Организации
{
query: {entity(People, field:=Name)}:person
or
{entity(Companies|Organizations)}:company
rule: key_words
// Поиск ключевых слов и фраз в текстах с найденными выше ключевыми компонентами
{
query: {macro(owner)
or orn(принадлежать, владеть, контролировать)}:owner_np
and
($person or $company)
rule_filter: singular
/* Ограничение поиска только внутри тех текстов, где ключевые слова,
обозначающие владельца, употреблены в единственном числе */
{
query: $owner_np & lemma(singular)
rule: owner_of
/* Поиск паттернов:
— Александр Ильин, совладелец компании "Томский региональный платежный сервис".
— Александр Филлипов был владельцем компании «Автореал».
— Фирма "Вуолы-Эко" принадлежит Олегу Лебедю.
Андрей Озеров владеет 000 "НФК" .
— Основной владелец «Северстали» Алексей Мордашов.*/
{
query: phrase({$person}:owner,
optional(orn(быть, стать)),
optional(orn(назвать, объявить)),
{$owner_np}:owner,
{$company}:owner)
or
phrase({$company}:owner,
{$owner_np}:owner,
{$person}:owner)
or
phrase({$owner_np}:owner,
{$company}:owner,
{$person}:owner)
result: Match = concat($owner_person, " ", $owner:owner_np, " ", $owner:company)
attribute: Владелец = toentity(People, $owner:person, field:=Name)
attribute: Компания = toentity(Companies_Organizations, $owner:company, field:=Name)
}
}
}
}Текст
Результат
